

In this post, we introduce the Generative AI Path-to-Value (P2V) framework, a structured approach to help you move generative AI initiatives from concept to production and sustained value creation.

We're excited to announce the launch of Amazon SageMaker JumpStart optimized deployments. SageMaker JumpStart improved deployments address the need for rich and straightforward deployment customization on SageMaker JumpStart by offering pre-defined deployment configurations, designed for specific use cases. Customers maintain the same level of visibility into the details of their proposed deployments, but now deployments are optimized for their specific use case and performance constraint.

This post explores how Amazon SageMaker HyperPod provides a comprehensive solution for inference workloads. We walk you through the platform’s key capabilities for dynamic scaling, simplified deployment, and intelligent resource management. By the end of this post, you’ll understand how to use the HyperPod automated infrastructure, cost optimization features, and performance enhancements to reduce your total cost of ownership by up to 40% while accelerating your generative AI deployments from concept to production.

In this post, we walk through how Guidesly built Jack AI on AWS using AWS Lambda, AWS Step Functions, Amazon Simple Storage Service (Amazon S3), Amazon Relational Database Service (Amazon RDS), Amazon SageMaker AI, and Amazon Bedrock to ingest trip media, enrich it with context, apply computer vision and generative AI, and publish marketing-ready content across multiple channels—securely, reliably, and at scale.

With the new Spring AI AgentCore SDK, you can build production-ready AI agents and run them on the highly scalable AgentCore Runtime. The Spring AI AgentCore SDK is an open source library that brings Amazon Bedrock AgentCore capabilities into Spring AI. In this post, we build an AI agent starting with a chat endpoint, then adding streaming responses, conversation memory, and tools for web browsing and code execution.

This post demonstrates how Lambda enables scalable, cost-effective reward functions for Amazon Nova customization. You'll learn to choose between Reinforcement Learning via Verifiable Rewards (RLVR) for objectively verifiable tasks and Reinforcement Learning via AI Feedback (RLAIF) for subjective evaluation, design multi-dimensional reward systems that help you prevent reward hacking, optimize Lambda functions for training scale, and monitor reward distributions with Amazon CloudWatch. Working code examples and deployment guidance are included to help you start experimenting.
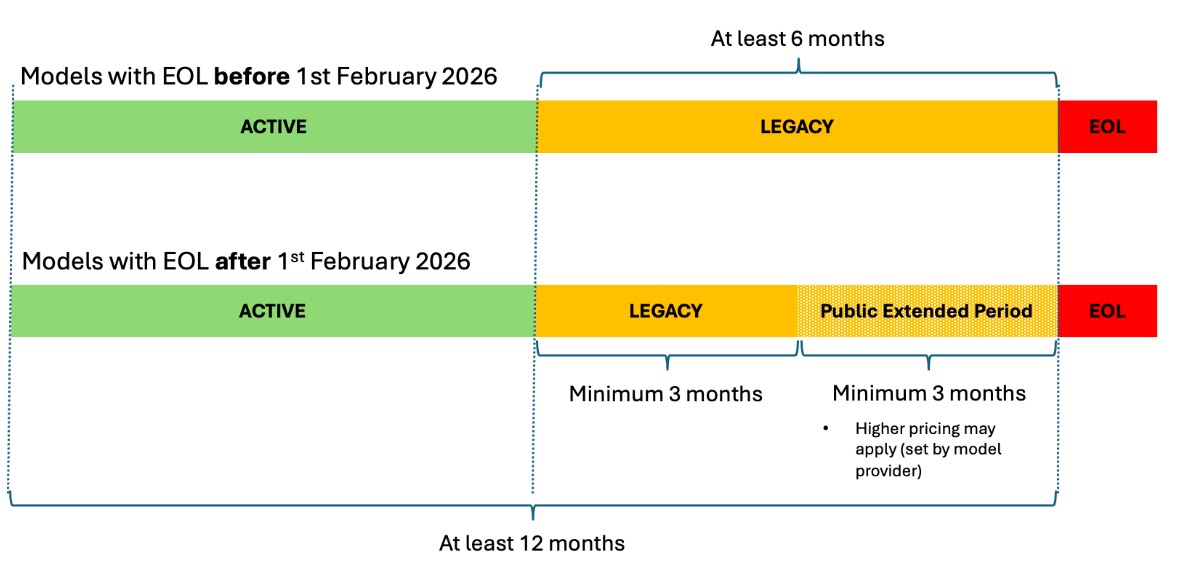
This post shows you how to manage FM transitions in Amazon Bedrock, so you can make sure your AI applications remain operational as models evolve. We discuss the three lifecycle states, how to plan migrations with the new extended access feature, and practical strategies to transition your applications to newer models without disruption.

Today, we're announcing AWS Agent Registry (preview) in AgentCore, a single place to discover, share, and reuse AI agents, tools, and agent skills across your enterprise.

This post walks you through three steps: starting a session and generating the Live View URL, rendering the stream in your React application, and wiring up an AI agent that drives the browser while your users watch. At the end, you will have a working sample application you can clone and run.

In this post, you will learn how to build stateful MCP servers that request user input during execution, invoke LLM sampling for dynamic content generation, and stream progress updates for long-running tasks. You will see code examples for each capability and deploy a working stateful MCP server to Amazon Bedrock AgentCore Runtime.

In this post, we'll walk you through a complete implementation of model fine-tuning in Amazon Bedrock using Amazon Nova models, demonstrating each step through an intent classifier example that achieves superior performance on a domain specific task. Throughout this guide, you'll learn to prepare high-quality training data that drives meaningful model improvements, configure hyperparameters to optimize learning without overfitting, and deploy your fine-tuned model for improved accuracy and reduced latency. We'll show you how to evaluate your results using training metrics and loss curves.

In healthcare and life sciences, AI agents help organizations process clinical data, submit regulatory filings, automate medical coding, and accelerate drug development and commercialization. However, the sensitive nature of healthcare data and regulatory requirements like Good Practice (GxP) compliance require human oversight at key decision points. This is where human-in-the-loop (HITL) constructs become essential. In this post, you will learn four practical approaches to implementing human-in-the-loop constructs using AWS services.

This post walks you through understanding audio embeddings, implementing Amazon Nova Multimodal Embeddings, and building a practical search system for your audio content. You'll learn how embeddings represent audio as vectors, explore the technical capabilities of Amazon Nova, and see hands-on code examples for indexing and querying your audio libraries. By the end, you'll have the knowledge to deploy production-ready audio search capabilities.

In this post, we explore where RFT is most effective, using the GSM8K mathematical reasoning dataset as a concrete example. We then walk through best practices for dataset preparation and reward function design, show how to monitor training progress using Amazon Bedrock metrics, and conclude with practical hyperparameter tuning guidelines informed by experiments across multiple models and use cases.

With Amazon Bedrock Projects, you can attribute inference costs to specific workloads and analyze them in AWS Cost Explorer and AWS Data Exports. In this post, you will learn how to set up Projects end-to-end, from designing a tagging strategy to analyzing costs.

This post walks through building an automated podcast generator that creates engaging conversations between two AI hosts on any topic, demonstrating the streaming capabilities of Nova Sonic, stage-aware content filtering, and real-time audio generation.

In this post, we show you how to build a natural text-to-SQL solution using Amazon Bedrock that transforms business questions into database queries and returns actionable answers.

In this post, we walk through building a custom HR onboarding agent with Quick. We show how to configure an agent that understands your organization’s processes, connects to your HR systems, and automates common tasks, such as answering new-hire questions and tracking document completion.

In this post, we walk through how we fine-tuned Qwen 2.5 7B Instruct for tool calling using RLVR. We cover dataset preparation across three distinct agent behaviors, reward function design with tiered scoring, training configuration and results interpretation, evaluation on held-out data with unseen tools, and deployment.

In this post, we show how to implement a generative AI agentic assistant that uses both semantic and text-based search using Amazon Bedrock, Amazon Bedrock AgentCore, Strands Agents and Amazon OpenSearch.

This blog post demonstrates how Windward helps enhance and accelerate alert investigation processes by combining geospatial intelligence with generative AI, enabling analysts to focus on decision-making rather than data collection.

Amazon Bedrock AgentCore Gateway provides a centralized layer for managing how AI agents connect to tools and MCP servers across your organization. In this post, we walk through how to configure AgentCore Gateway to connect to an OAuth-protected MCP server using the Authorization Code flow.

In this post, we explore how ActorSimulator in Strands Evaluations SDK addresses the challenge with structured user simulation that integrates into your evaluation pipeline.

This post describes how TGS achieved near-linear scaling for distributed training and expanded context windows for their Vision Transformer-based SFM using Amazon SageMaker HyperPod. This joint solution cut training time from 6 months to just 5 days while enabling analysis of seismic volumes larger than previously possible.

In this post, we show you how to configure AWS Network Firewall to restrict AgentCore resources to an allowlist of approved internet domains. This post focuses on domain-level filtering using SNI inspection — the first layer of a defense-in-depth approach.

Through a strategic partnership with the AWS Generative AI Innovation Center (GenAIIC), Rocket Close developed an intelligent document processing solution that has significantly reduced processing time, making the process 15 times faster. The solution, which uses Amazon Textract for OCR processing and Amazon Bedrock for foundation models (FMs), achieves a strong 90% overall accuracy in document segmentation, classification, and field extraction.

In this post, we go through how to use managed session storage to persist your agent's filesystem state and how to execute shell commands directly in your agent's environment.

This post demonstrates how to build an automated competitive price intelligence system that streamlines manual workflows, supporting teams to make data-driven pricing decisions with real-time market insights.

In this post, we introduce Amazon Bedrock AgentCore Evaluations, a fully managed service for assessing AI agent performance across the development lifecycle. We walk through how the service measures agent accuracy across multiple quality dimensions. We explain the two evaluation approaches for development and production and share practical guidance for building agents you can deploy with confidence.

In this post, you learn how to build a FinOps agent using Amazon Bedrock AgentCore that helps your finance team manage AWS costs across multiple accounts. This conversational agent consolidates data from AWS Cost Explorer, AWS Budgets, and AWS Compute Optimizer into a single interface, so your team can ask questions like "What are my top cost drivers this month?" and receive immediate answers.

In this post, we show you how to build a similar system for your organization. You will learn the architecture decisions, implementation details, and deployment process that can help you automate your own compliance workflows.

In this post, we demonstrate how to implement agentic QA automation through QA Studio, a reference solution built with Amazon Nova Act. You will see how to define tests in natural language that adapt automatically to UI changes, explore the serverless architecture that executes tests reliably at scale, and get step-by-step deployment guidance for your AWS environment.

I'm excited to announce that AWS Security Agent on-demand penetration testing and AWS DevOps Agent are now generally available, representing a new class of AI capabilities we announced at re:Invent called frontier agents. These autonomous systems work independently to achieve goals, scale massively to tackle concurrent tasks, and run persistently for hours or days without constant human oversight. Together, these agents are changing the way we secure and operate software. In preview, customers and partners report that AWS Security Agent compresses penetration testing timelines from weeks to hours and the AWS DevOps Agent supports 3–5x faster incident resolution.

Traditional frameworks designed for static deployments cannot address the dynamic interactions that define agentic workloads. AI Risk Intelligence (AIRI), from AWS Generative AI Innovation Center, provides the automated rigor required to govern agents at enterprise scale—a fundamental reimagining of how security, operations, and governance work together systemically.

In this post, you'll learn how Ring implemented metadata-driven filtering for Region-specific content, separated content management into ingestion, evaluation and promotion workflows, and achieved cost savings while scaling up.

In this post, we explore the challenges that Volkswagen Group faced in producing brand-compliant marketing assets at scale. We walk through how we built a generative AI solution that generates photorealistic vehicle images, validates technical accuracy at the component level, and helps enforce brand guideline compliance alignment across the ten brands.

In this post, we show you how to use Amazon SageMaker AI to build and deploy a deep learning model for detecting solar flares using data from the European Space Agency's STIX instrument.

In this post, we walk through two use cases that help enhance the user viewing experience using agentic AI tools and frameworks including Strands Agents SDK, Amazon Bedrock AgentCore, and Amazon Nova Sonic 2.0. This agentic AI system uses a Model Context Protocol (MCP) to deliver a personal entertainment concierge that understands user preferences through natural dialogue.

Today, we’re excited to announce that Amazon Bedrock is now available in the Asia Pacific (New Zealand) Region (ap-southeast-6). Customers in New Zealand can now access Anthropic Claude models (Claude Opus 4.5, Opus 4.6, Sonnet 4.5, Sonnet 4.6, and Haiku 4.5) and Amazon (Nova 2 Lite) models directly in the Auckland Region with cross region inference. In this post, we explore how cross-Region inference works from the New Zealand Region, the models available through geographic and global routing, and how to get started with your first API call. We

In this post, we walk you through how to implement a fully automated, context-aware AI solution using a serverless architecture on AWS. This solution helps organizations looking to deploy responsible AI systems, align with compliance requirements for vulnerable populations, and help maintain appropriate and trustworthy AI responses across diverse user groups without compromising performance or governance.

Last year, AWS announced an integration between Amazon SageMaker Unified Studio and Amazon S3 general purpose buckets. This integration makes it straightforward for teams to use unstructured data stored in Amazon Simple Storage Service (Amazon S3) for machine learning (ML) and data analytics use cases. In this post, we show how to integrate S3 general purpose buckets with Amazon SageMaker Catalog to fine-tune Llama 3.2 11B Vision Instruct for visual question answering (VQA) using Amazon SageMaker Unified Studio.

Today, we’re excited to announce the new Bidirectional Streaming API for Amazon Polly, enabling streamlined real-time text-to-speech (TTS) synthesis where you can start sending text and receiving audio simultaneously. This new API is built for conversational AI applications that generate text or audio incrementally, like responses from large language models (LLMs), where users must begin synthesizing audio before the full text is available.

In this post, we explore how the multimodal foundation models (FMs) of Amazon Bedrock enable scalable video understanding through three distinct architectural approaches. Each approach is designed for different use cases and cost-performance trade-offs.

In this series of posts, you will learn how streaming architectures help address these challenges using Pipecat voice agents on Amazon Bedrock AgentCore Runtime. In Part 1, you will learn how to deploy Pipecat voice agents on AgentCore Runtime using different network transport approaches including WebSockets, WebRTC and telephony integration, with practical deployment guidance and code samples.

In this post, we walk through the end-to-end workflow of using RFT on Amazon Bedrock with OpenAI-compatible APIs: from setting up authentication, to deploying a Lambda-based reward function, to kicking off a training job and running on-demand inference on your fine-tuned model.

In this post, we walk through how to search for available p-family GPU capacity, create a training plan reservation for inference, and deploy a SageMaker AI inference endpoint on that reserved capacity. We follow a data scientist's journey as they reserve capacity for model evaluation and manage the endpoint throughout the reservation lifecycle.

This post introduces Claude Tool use in Amazon Bedrock which uses the power of large language models (LLMs) to perform dynamic, adaptable entity recognition without extensive setup or training.

In this blog post, we show you how Reco implemented Amazon Bedrock to help transform security alerts and achieve significant improvements in incident response times.

In this post, we demonstrate how to build a Slack integration using AWS Cloud Development Kit (AWS CDK). You will learn how to deploy the infrastructure with three specialized AWS Lambda functions, configure event subscriptions properly to handle Slack's security requirements, and implement conversation management patterns that work for many agent use cases.

In this post, we’re excited to showcase how AWS ISV Partner Artificial Genius is using Amazon SageMaker AI and Amazon Nova to deliver a solution that is probabilistic on input but deterministic on output, helping to enable safe, enterprise-grade adoption.

This post explores the technical characteristics of the Nemotron 3 Super model and discusses potential application use cases. It also provides technical guidance to get started using this model for your generative AI applications within the Amazon Bedrock environment.

In this post, we explore our approach to video generation through VRAG, transforming natural language text prompts and images into grounded, high-quality videos. Through this fully automated solution, you can generate realistic, AI-powered video sequences from structured text and image inputs, streamlining the video creation process.

This post introduces Video Retrieval-Augmented Generation (V-RAG), an approach to help improve video content creation. By combining retrieval augmented generation with advanced video AI models, V-RAG offers an efficient, and reliable solution for generating AI videos.

SageMaker AI endpoints now support enhanced metrics with configurable publishing frequency. This launch provides the granular visibility needed to monitor, troubleshoot, and improve your production endpoints.

In this post, we walk you through the process of using the Nova Forge SDK to train an Amazon Nova model using Amazon SageMaker AI Training Jobs.

Today, we are launching Nova Forge SDK that makes LLM customization accessible, empowering teams to harness the full potential of language models without the challenges of dependency management, image selection, and recipe configuration and eventually lowering the barrier of entry.

In this post, we show how to evaluate AI agents systematically using Strands Evals. We walk through the core concepts, built-in evaluators, multi-turn simulation capabilities and practical approaches and patterns for integration.

This post shows you how to build an AI-powered A/B testing engine using Amazon Bedrock, Amazon Elastic Container Service, Amazon DynamoDB, and the Model Context Protocol (MCP). The system improves traditional A/B testing by analyzing user context to make smarter variant assignment decisions during the experiment.

Working with the AWS Generative AI Innovation Center, Bark developed an AI-powered content generation solution that demonstrated a substantial reduction in production time in experimental trials while improving content quality scores. In this post, we walk you through the technical architecture we built, the key design decisions that contributed to success, and the measurable results achieved, giving you a blueprint for implementing similar solutions.

In this post, you will learn how to migrate from Nova 1 to Nova 2 on Amazon Bedrock. We cover model mapping, API changes, code examples using the Converse API, guidance on configuring new capabilities, and a summary of use cases. We conclude with a migration checklist to help you plan and execute your transition.

In this post, we’ll explore how Atos used the AWS AI League to help accelerate AI education across 400+ participants, highlight the tangible benefits of gamified, experiential learning, and share actionable insights you can apply to your own AI enablement programs.
Today at NVIDIA GTC 2026, AWS and NVIDIA announced an expanded collaboration with new technology integrations to support growing AI compute demand and help you build and run AI solutions that are production-ready.

This is Part II of a two-part series from the AWS Generative AI Innovation Center. In Part II, we speak directly to the leaders who must turn that shared foundation into action. Each role carries a distinct set of responsibilities, risks, and leverage points. Whether you own a P&L, run enterprise architecture, lead security, govern data, or manage compliance, this section is written in the language of your job—because that's where agentic AI either succeeds or quietly dies.

In this blog post, we introduce the concepts behind next-generation inference capabilities, including disaggregated serving, intelligent request scheduling, and expert parallelism. We discuss their benefits and walk through how you can implement them on Amazon SageMaker HyperPod EKS to achieve significant improvements in inference performance, resource utilization, and operational efficiency.

This blog post provides step-by-step guidance on implementing an offline feature store using SageMaker Catalog within a SageMaker Unified Studio domain. By adopting a publish-subscribe pattern, data producers can use this solution to publish curated, versioned feature tables—while data consumers can securely discover, subscribe to, and reuse them for model development.