

In this post, we show how connecting the Visier Workforce AI platform with Amazon Quick through Model Context Protocol (MCP) gives every knowledge worker a unified agentic workspace to ask questions in. Visier helps ground the workspace in live workforce data and the organizational context that surrounds it while letting your users act on the conversational results without switching tools.
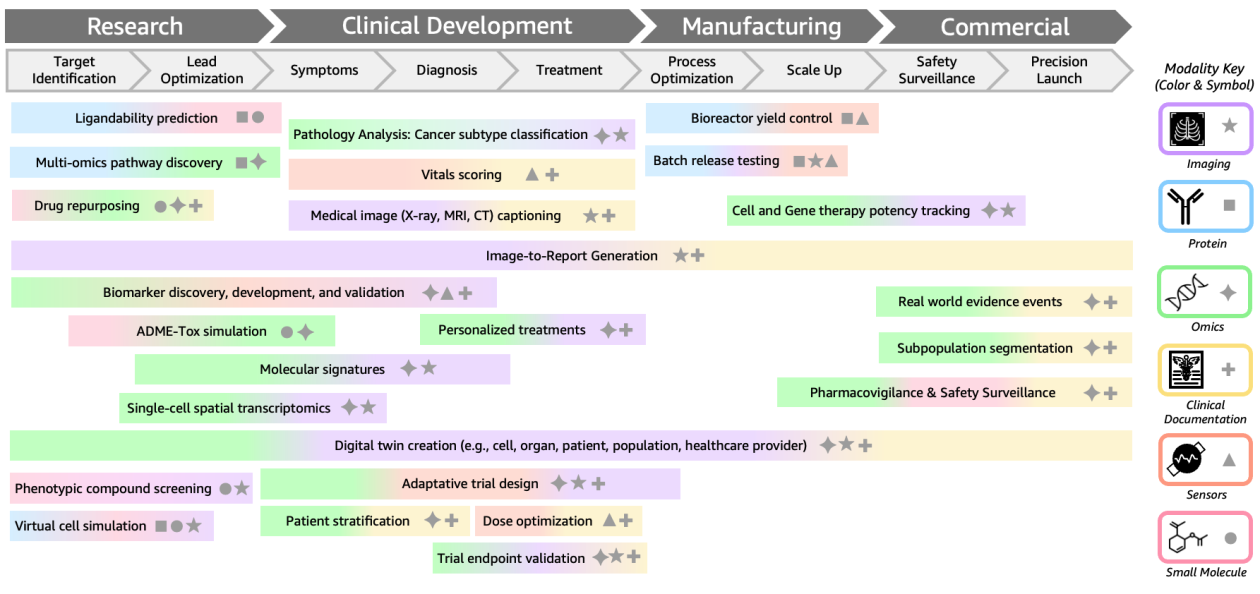
In this post, we'll explore how multimodal BioFMs work, showcase real-world applications in drug discovery and clinical development, and contextualize how AWS enables organizations to build and deploy multimodal BioFMs.

In this post, we walk through building a scalable, event-driven transcription pipeline that automatically processes audio files uploaded to Amazon Simple Storage Service (Amazon S3), and show you how to use Amazon EC2 Spot Instances and buffered streaming inference to further reduce costs.

Today, Amazon SageMaker AI supports optimized generative AI inference recommendations. By delivering validated, optimal deployment configurations with performance metrics, Amazon SageMaker AI keeps your model developers focused on building accurate models, not managing infrastructure.

Today, we're introducing new capabilities that further streamline the agent building experience, removing the infrastructure barriers that slow teams down at every stage of agent development from the first prototype through production deployment.

Company-wise memory in Amazon Bedrock, powered by Amazon Neptune and Mem0, provides AI agents with persistent, company-specific context—enabling them to learn, adapt, and respond intelligently across multiple interactions. TrendMicro, one of the largest antivirus software companies in the world, developed the Trend’s Companion chatbot, so their customers can explore information through natural, conversational interactions

Today, we're excited to announce Claude Cowork in Amazon Bedrock. You can now run Cowork and Claude Code Desktop through Amazon Bedrock, directly or using an LLM gateway. In this post, we walk through how Claude Cowork integrates with Amazon Bedrock and show an example of how knowledge workers use it in practice.

In this post, we show how to combine DVC (Data Version Control), Amazon SageMaker AI, and Amazon SageMaker AI MLflow Apps to build end-to-end ML model lineage. We walk through two deployable patterns — dataset-level lineage and record-level lineage — that you can run in your own AWS account using the companion notebooks.

Today, we are thrilled to announce the availability of G7e instances powered by NVIDIA RTX PRO 6000 Blackwell Server Edition GPUs on Amazon SageMaker AI. You can provision nodes with 1, 2, 4, and 8 RTX PRO 6000 GPU instances, with each GPU providing 96 GB of GDDR7 memory. This launch provides the capability to use a single-node GPU, G7e.2xlarge instance to host powerful open source foundation models (FMs) like GPT-OSS-120B, Nemotron-3-Super-120B-A12B (NVFP4 variant), and Qwen3.5-35B-A3B, offering organizations a cost-effective and high-performing option.

You can use ToolSimulator, an LLM-powered tool simulation framework within Strands Evals, to thoroughly and safely test AI agents that rely on external tools, at scale. Instead of risking live API calls that expose personally identifiable information (PII), trigger unintended actions, or settling for static mocks that break with multi-turn workflows, you can use ToolSimulator's large language model (LLM)-powered simulations to validate your agents. Available today as part of the Strands Evals Software Development Kit (SDK), ToolSimulator helps you catch integration bugs early, test edge cases comprehensively, and ship production-ready agents with confidence.

In this post, we'll show you how to build a complete omnichannel ordering system using Amazon Bedrock AgentCore, an agentic platform, to build, deploy, and operate highly effective AI agents securely at scale using any framework and foundation model and Amazon Nova 2 Sonic.

In this post, we share how Amazon Bedrock's granular cost attribution works and walk through example cost tracking scenarios.

In this post, we show you how to use Model Distillation, a model customization technique on Amazon Bedrock, to transfer routing intelligence from a large teacher model (Amazon Nova Premier) into a much smaller student model (Amazon Nova Micro). This approach cuts inference cost by over 95% and reduces latency by 50% while maintaining the nuanced routing quality that the task demands.

In this post, we show you how to build a video semantic search solution on Amazon Bedrock using Nova Multimodal Embeddings that intelligently understands user intent and retrieves accurate video results across all signal types simultaneously. We also share a reference implementation you can deploy and explore with your own content.

This hands-on guide walks through every step of fine-tuning an Amazon Nova model with the Amazon Nova Forge SDK, from data preparation to training with data mixing to evaluation, giving you a repeatable playbook you can adapt to your own use case. This is the second part in our Nova Forge SDK series, building on the SDK introduction and first part, which covered kicking off customization experiments.

In this post, we share how AWS Marketing’s Technology, AI, and Analytics (TAA) team worked with Gradial to build an agentic AI solution on Amazon Bedrock for accelerating content publishing workflows.

In this post, we demonstrate two approaches to fine-tune Amazon Nova Micro for custom SQL dialect generation to deliver both cost efficiency and production ready performance.

Online retailers face a persistent challenge: shoppers struggle to determine the fit and look when ordering online, leading to increased returns and decreased purchase confidence. The cost? Lost revenue, operational overhead, and customer frustration. Meanwhile, consumers increasingly expect immersive, interactive shopping experiences that bridge the gap between online and in-store retail. Retailers implementing virtual try-on […]

In this post, you'll learn why probabilistic AI validation falls short in regulated industries and how Automated Reasoning checks use formal verification to deliver mathematically proven results. You'll also see how customers across six industries use this technology to produce formally verified, auditable AI outputs, and how to get started.

In this post, you will learn how speculative decoding works and why it helps reduce cost per generated token on AWS Trainium2.

This post is cowritten by Renata Salvador Grande, Gabriel Bueno and Paulo Laurentys at Rede Mater Dei de Saúde. The growing adoption of multi-agent AI systems is redefining critical operations in healthcare. In large hospital networks, where thousands of decisions directly impact cash flow, service delivery times, and the risk of claim denials, the ability […]

In this post, we introduce the Generative AI Path-to-Value (P2V) framework, a structured approach to help you move generative AI initiatives from concept to production and sustained value creation.

We're excited to announce the launch of Amazon SageMaker JumpStart optimized deployments. SageMaker JumpStart improved deployments address the need for rich and straightforward deployment customization on SageMaker JumpStart by offering pre-defined deployment configurations, designed for specific use cases. Customers maintain the same level of visibility into the details of their proposed deployments, but now deployments are optimized for their specific use case and performance constraint.

This post explores how Amazon SageMaker HyperPod provides a comprehensive solution for inference workloads. We walk you through the platform’s key capabilities for dynamic scaling, simplified deployment, and intelligent resource management. By the end of this post, you’ll understand how to use the HyperPod automated infrastructure, cost optimization features, and performance enhancements to reduce your total cost of ownership by up to 40% while accelerating your generative AI deployments from concept to production.

In this post, we walk through how Guidesly built Jack AI on AWS using AWS Lambda, AWS Step Functions, Amazon Simple Storage Service (Amazon S3), Amazon Relational Database Service (Amazon RDS), Amazon SageMaker AI, and Amazon Bedrock to ingest trip media, enrich it with context, apply computer vision and generative AI, and publish marketing-ready content across multiple channels—securely, reliably, and at scale.

With the new Spring AI AgentCore SDK, you can build production-ready AI agents and run them on the highly scalable AgentCore Runtime. The Spring AI AgentCore SDK is an open source library that brings Amazon Bedrock AgentCore capabilities into Spring AI. In this post, we build an AI agent starting with a chat endpoint, then adding streaming responses, conversation memory, and tools for web browsing and code execution.

This post demonstrates how Lambda enables scalable, cost-effective reward functions for Amazon Nova customization. You'll learn to choose between Reinforcement Learning via Verifiable Rewards (RLVR) for objectively verifiable tasks and Reinforcement Learning via AI Feedback (RLAIF) for subjective evaluation, design multi-dimensional reward systems that help you prevent reward hacking, optimize Lambda functions for training scale, and monitor reward distributions with Amazon CloudWatch. Working code examples and deployment guidance are included to help you start experimenting.
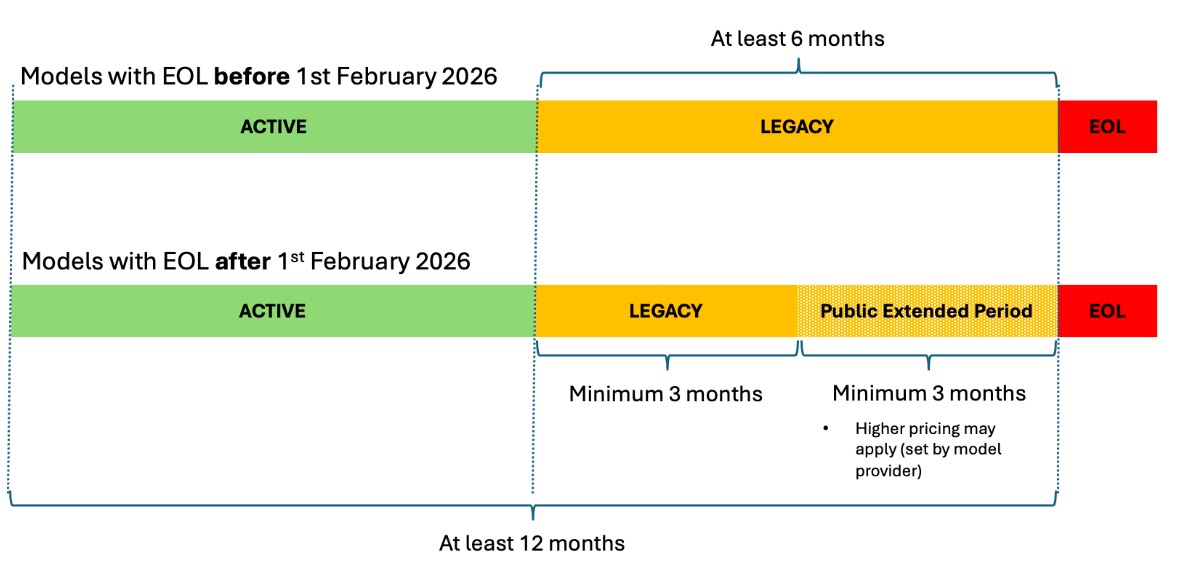
This post shows you how to manage FM transitions in Amazon Bedrock, so you can make sure your AI applications remain operational as models evolve. We discuss the three lifecycle states, how to plan migrations with the new extended access feature, and practical strategies to transition your applications to newer models without disruption.

Today, we're announcing AWS Agent Registry (preview) in AgentCore, a single place to discover, share, and reuse AI agents, tools, and agent skills across your enterprise.

This post walks you through three steps: starting a session and generating the Live View URL, rendering the stream in your React application, and wiring up an AI agent that drives the browser while your users watch. At the end, you will have a working sample application you can clone and run.

In this post, you will learn how to build stateful MCP servers that request user input during execution, invoke LLM sampling for dynamic content generation, and stream progress updates for long-running tasks. You will see code examples for each capability and deploy a working stateful MCP server to Amazon Bedrock AgentCore Runtime.

In this post, we'll walk you through a complete implementation of model fine-tuning in Amazon Bedrock using Amazon Nova models, demonstrating each step through an intent classifier example that achieves superior performance on a domain specific task. Throughout this guide, you'll learn to prepare high-quality training data that drives meaningful model improvements, configure hyperparameters to optimize learning without overfitting, and deploy your fine-tuned model for improved accuracy and reduced latency. We'll show you how to evaluate your results using training metrics and loss curves.

In healthcare and life sciences, AI agents help organizations process clinical data, submit regulatory filings, automate medical coding, and accelerate drug development and commercialization. However, the sensitive nature of healthcare data and regulatory requirements like Good Practice (GxP) compliance require human oversight at key decision points. This is where human-in-the-loop (HITL) constructs become essential. In this post, you will learn four practical approaches to implementing human-in-the-loop constructs using AWS services.

This post walks you through understanding audio embeddings, implementing Amazon Nova Multimodal Embeddings, and building a practical search system for your audio content. You'll learn how embeddings represent audio as vectors, explore the technical capabilities of Amazon Nova, and see hands-on code examples for indexing and querying your audio libraries. By the end, you'll have the knowledge to deploy production-ready audio search capabilities.

In this post, we explore where RFT is most effective, using the GSM8K mathematical reasoning dataset as a concrete example. We then walk through best practices for dataset preparation and reward function design, show how to monitor training progress using Amazon Bedrock metrics, and conclude with practical hyperparameter tuning guidelines informed by experiments across multiple models and use cases.

With Amazon Bedrock Projects, you can attribute inference costs to specific workloads and analyze them in AWS Cost Explorer and AWS Data Exports. In this post, you will learn how to set up Projects end-to-end, from designing a tagging strategy to analyzing costs.

This post walks through building an automated podcast generator that creates engaging conversations between two AI hosts on any topic, demonstrating the streaming capabilities of Nova Sonic, stage-aware content filtering, and real-time audio generation.

In this post, we show you how to build a natural text-to-SQL solution using Amazon Bedrock that transforms business questions into database queries and returns actionable answers.

In this post, we walk through building a custom HR onboarding agent with Quick. We show how to configure an agent that understands your organization’s processes, connects to your HR systems, and automates common tasks, such as answering new-hire questions and tracking document completion.

In this post, we walk through how we fine-tuned Qwen 2.5 7B Instruct for tool calling using RLVR. We cover dataset preparation across three distinct agent behaviors, reward function design with tiered scoring, training configuration and results interpretation, evaluation on held-out data with unseen tools, and deployment.

In this post, we show how to implement a generative AI agentic assistant that uses both semantic and text-based search using Amazon Bedrock, Amazon Bedrock AgentCore, Strands Agents and Amazon OpenSearch.

This blog post demonstrates how Windward helps enhance and accelerate alert investigation processes by combining geospatial intelligence with generative AI, enabling analysts to focus on decision-making rather than data collection.

Amazon Bedrock AgentCore Gateway provides a centralized layer for managing how AI agents connect to tools and MCP servers across your organization. In this post, we walk through how to configure AgentCore Gateway to connect to an OAuth-protected MCP server using the Authorization Code flow.

In this post, we explore how ActorSimulator in Strands Evaluations SDK addresses the challenge with structured user simulation that integrates into your evaluation pipeline.

This post describes how TGS achieved near-linear scaling for distributed training and expanded context windows for their Vision Transformer-based SFM using Amazon SageMaker HyperPod. This joint solution cut training time from 6 months to just 5 days while enabling analysis of seismic volumes larger than previously possible.

In this post, we show you how to configure AWS Network Firewall to restrict AgentCore resources to an allowlist of approved internet domains. This post focuses on domain-level filtering using SNI inspection — the first layer of a defense-in-depth approach.

Through a strategic partnership with the AWS Generative AI Innovation Center (GenAIIC), Rocket Close developed an intelligent document processing solution that has significantly reduced processing time, making the process 15 times faster. The solution, which uses Amazon Textract for OCR processing and Amazon Bedrock for foundation models (FMs), achieves a strong 90% overall accuracy in document segmentation, classification, and field extraction.

In this post, we go through how to use managed session storage to persist your agent's filesystem state and how to execute shell commands directly in your agent's environment.

This post demonstrates how to build an automated competitive price intelligence system that streamlines manual workflows, supporting teams to make data-driven pricing decisions with real-time market insights.

In this post, we introduce Amazon Bedrock AgentCore Evaluations, a fully managed service for assessing AI agent performance across the development lifecycle. We walk through how the service measures agent accuracy across multiple quality dimensions. We explain the two evaluation approaches for development and production and share practical guidance for building agents you can deploy with confidence.

In this post, you learn how to build a FinOps agent using Amazon Bedrock AgentCore that helps your finance team manage AWS costs across multiple accounts. This conversational agent consolidates data from AWS Cost Explorer, AWS Budgets, and AWS Compute Optimizer into a single interface, so your team can ask questions like "What are my top cost drivers this month?" and receive immediate answers.

In this post, we show you how to build a similar system for your organization. You will learn the architecture decisions, implementation details, and deployment process that can help you automate your own compliance workflows.

In this post, we demonstrate how to implement agentic QA automation through QA Studio, a reference solution built with Amazon Nova Act. You will see how to define tests in natural language that adapt automatically to UI changes, explore the serverless architecture that executes tests reliably at scale, and get step-by-step deployment guidance for your AWS environment.

I'm excited to announce that AWS Security Agent on-demand penetration testing and AWS DevOps Agent are now generally available, representing a new class of AI capabilities we announced at re:Invent called frontier agents. These autonomous systems work independently to achieve goals, scale massively to tackle concurrent tasks, and run persistently for hours or days without constant human oversight. Together, these agents are changing the way we secure and operate software. In preview, customers and partners report that AWS Security Agent compresses penetration testing timelines from weeks to hours and the AWS DevOps Agent supports 3–5x faster incident resolution.

Traditional frameworks designed for static deployments cannot address the dynamic interactions that define agentic workloads. AI Risk Intelligence (AIRI), from AWS Generative AI Innovation Center, provides the automated rigor required to govern agents at enterprise scale—a fundamental reimagining of how security, operations, and governance work together systemically.

In this post, you'll learn how Ring implemented metadata-driven filtering for Region-specific content, separated content management into ingestion, evaluation and promotion workflows, and achieved cost savings while scaling up.

In this post, we explore the challenges that Volkswagen Group faced in producing brand-compliant marketing assets at scale. We walk through how we built a generative AI solution that generates photorealistic vehicle images, validates technical accuracy at the component level, and helps enforce brand guideline compliance alignment across the ten brands.

In this post, we show you how to use Amazon SageMaker AI to build and deploy a deep learning model for detecting solar flares using data from the European Space Agency's STIX instrument.

In this post, we walk through two use cases that help enhance the user viewing experience using agentic AI tools and frameworks including Strands Agents SDK, Amazon Bedrock AgentCore, and Amazon Nova Sonic 2.0. This agentic AI system uses a Model Context Protocol (MCP) to deliver a personal entertainment concierge that understands user preferences through natural dialogue.

Today, we’re excited to announce that Amazon Bedrock is now available in the Asia Pacific (New Zealand) Region (ap-southeast-6). Customers in New Zealand can now access Anthropic Claude models (Claude Opus 4.5, Opus 4.6, Sonnet 4.5, Sonnet 4.6, and Haiku 4.5) and Amazon (Nova 2 Lite) models directly in the Auckland Region with cross region inference. In this post, we explore how cross-Region inference works from the New Zealand Region, the models available through geographic and global routing, and how to get started with your first API call. We

In this post, we walk you through how to implement a fully automated, context-aware AI solution using a serverless architecture on AWS. This solution helps organizations looking to deploy responsible AI systems, align with compliance requirements for vulnerable populations, and help maintain appropriate and trustworthy AI responses across diverse user groups without compromising performance or governance.

Last year, AWS announced an integration between Amazon SageMaker Unified Studio and Amazon S3 general purpose buckets. This integration makes it straightforward for teams to use unstructured data stored in Amazon Simple Storage Service (Amazon S3) for machine learning (ML) and data analytics use cases. In this post, we show how to integrate S3 general purpose buckets with Amazon SageMaker Catalog to fine-tune Llama 3.2 11B Vision Instruct for visual question answering (VQA) using Amazon SageMaker Unified Studio.

Today, we’re excited to announce the new Bidirectional Streaming API for Amazon Polly, enabling streamlined real-time text-to-speech (TTS) synthesis where you can start sending text and receiving audio simultaneously. This new API is built for conversational AI applications that generate text or audio incrementally, like responses from large language models (LLMs), where users must begin synthesizing audio before the full text is available.

In this post, we explore how the multimodal foundation models (FMs) of Amazon Bedrock enable scalable video understanding through three distinct architectural approaches. Each approach is designed for different use cases and cost-performance trade-offs.

In this series of posts, you will learn how streaming architectures help address these challenges using Pipecat voice agents on Amazon Bedrock AgentCore Runtime. In Part 1, you will learn how to deploy Pipecat voice agents on AgentCore Runtime using different network transport approaches including WebSockets, WebRTC and telephony integration, with practical deployment guidance and code samples.

In this post, we walk through the end-to-end workflow of using RFT on Amazon Bedrock with OpenAI-compatible APIs: from setting up authentication, to deploying a Lambda-based reward function, to kicking off a training job and running on-demand inference on your fine-tuned model.

In this post, we walk through how to search for available p-family GPU capacity, create a training plan reservation for inference, and deploy a SageMaker AI inference endpoint on that reserved capacity. We follow a data scientist's journey as they reserve capacity for model evaluation and manage the endpoint throughout the reservation lifecycle.

This post introduces Claude Tool use in Amazon Bedrock which uses the power of large language models (LLMs) to perform dynamic, adaptable entity recognition without extensive setup or training.

In this blog post, we show you how Reco implemented Amazon Bedrock to help transform security alerts and achieve significant improvements in incident response times.

In this post, we demonstrate how to build a Slack integration using AWS Cloud Development Kit (AWS CDK). You will learn how to deploy the infrastructure with three specialized AWS Lambda functions, configure event subscriptions properly to handle Slack's security requirements, and implement conversation management patterns that work for many agent use cases.

In this post, we’re excited to showcase how AWS ISV Partner Artificial Genius is using Amazon SageMaker AI and Amazon Nova to deliver a solution that is probabilistic on input but deterministic on output, helping to enable safe, enterprise-grade adoption.

This post explores the technical characteristics of the Nemotron 3 Super model and discusses potential application use cases. It also provides technical guidance to get started using this model for your generative AI applications within the Amazon Bedrock environment.

In this post, we explore our approach to video generation through VRAG, transforming natural language text prompts and images into grounded, high-quality videos. Through this fully automated solution, you can generate realistic, AI-powered video sequences from structured text and image inputs, streamlining the video creation process.

This post introduces Video Retrieval-Augmented Generation (V-RAG), an approach to help improve video content creation. By combining retrieval augmented generation with advanced video AI models, V-RAG offers an efficient, and reliable solution for generating AI videos.

SageMaker AI endpoints now support enhanced metrics with configurable publishing frequency. This launch provides the granular visibility needed to monitor, troubleshoot, and improve your production endpoints.

In this post, we walk you through the process of using the Nova Forge SDK to train an Amazon Nova model using Amazon SageMaker AI Training Jobs.

Today, we are launching Nova Forge SDK that makes LLM customization accessible, empowering teams to harness the full potential of language models without the challenges of dependency management, image selection, and recipe configuration and eventually lowering the barrier of entry.

In this post, we show how to evaluate AI agents systematically using Strands Evals. We walk through the core concepts, built-in evaluators, multi-turn simulation capabilities and practical approaches and patterns for integration.

This post shows you how to build an AI-powered A/B testing engine using Amazon Bedrock, Amazon Elastic Container Service, Amazon DynamoDB, and the Model Context Protocol (MCP). The system improves traditional A/B testing by analyzing user context to make smarter variant assignment decisions during the experiment.

Working with the AWS Generative AI Innovation Center, Bark developed an AI-powered content generation solution that demonstrated a substantial reduction in production time in experimental trials while improving content quality scores. In this post, we walk you through the technical architecture we built, the key design decisions that contributed to success, and the measurable results achieved, giving you a blueprint for implementing similar solutions.

In this post, you will learn how to migrate from Nova 1 to Nova 2 on Amazon Bedrock. We cover model mapping, API changes, code examples using the Converse API, guidance on configuring new capabilities, and a summary of use cases. We conclude with a migration checklist to help you plan and execute your transition.

In this post, we’ll explore how Atos used the AWS AI League to help accelerate AI education across 400+ participants, highlight the tangible benefits of gamified, experiential learning, and share actionable insights you can apply to your own AI enablement programs.
Today at NVIDIA GTC 2026, AWS and NVIDIA announced an expanded collaboration with new technology integrations to support growing AI compute demand and help you build and run AI solutions that are production-ready.

This is Part II of a two-part series from the AWS Generative AI Innovation Center. In Part II, we speak directly to the leaders who must turn that shared foundation into action. Each role carries a distinct set of responsibilities, risks, and leverage points. Whether you own a P&L, run enterprise architecture, lead security, govern data, or manage compliance, this section is written in the language of your job—because that's where agentic AI either succeeds or quietly dies.

In this blog post, we introduce the concepts behind next-generation inference capabilities, including disaggregated serving, intelligent request scheduling, and expert parallelism. We discuss their benefits and walk through how you can implement them on Amazon SageMaker HyperPod EKS to achieve significant improvements in inference performance, resource utilization, and operational efficiency.

This blog post provides step-by-step guidance on implementing an offline feature store using SageMaker Catalog within a SageMaker Unified Studio domain. By adopting a publish-subscribe pattern, data producers can use this solution to publish curated, versioned feature tables—while data consumers can securely discover, subscribe to, and reuse them for model development.

In this post, we explain how P-EAGLE works, how we integrated it into vLLM starting from v0.16.0 (PR#32887), and how to serve it with our pre-trained checkpoints.

Today, we’re announcing two new Amazon CloudWatch metrics for Amazon Bedrock, TimeToFirstToken and EstimatedTPMQuotaUsage. In this post, we cover how these work and how to set alarms, establish baselines, and proactively manage capacity using them.

In this post, you will understand how Policy in Amazon Bedrock AgentCore creates a deterministic enforcement layer that operates independently of the agent's own reasoning. You will learn how to turn natural language descriptions of your business rules into Cedar policies, then use those policies to enforce fine-grained, identity-aware controls so that agents only access the tools and data that their users are authorized to use. You will also see how to apply Policy through AgentCore Gateway, intercepting and evaluating every agent-to-tool request at runtime.

This post shows you how to build a scalable multimodal video search system that enables natural language search across large video datasets using Amazon Nova models and Amazon OpenSearch Service. You will learn how to move beyond manual tagging and keyword-based searches to enable semantic search that captures the full richness of video content.

In this post, we explore how to fine-tune a leaderboard-topping, NVIDIA Nemotron Speech Automatic Speech Recognition (ASR) model; Parakeet TDT 0.6B V2. Using synthetic speech data to achieve superior transcription results for specialised applications, we'll walk through an end-to-end workflow that combines AWS infrastructure with the following popular open-source frameworks.

The AWS Generative AI Innovation Center has helped 1,000+ customers move AI into production, delivering millions in documented productivity gains. In this post, we share guidance for leaders across the C-suite: CTOs, CISOs, CDOs, and Chief Data Science/AI officers, as well as business owners and compliance leads.

In this post, we show how to fine-tune a Llama model using Oumi on Amazon EC2 (with the option to create synthetic data using Oumi), store artifacts in Amazon S3, and deploy to Amazon Bedrock using Custom Model Import for managed inference.

We are excited to announce that NVIDIA’s Nemotron 3 Nano is now available as a fully managed and serverless model in Amazon Bedrock. This follows our earlier announcement at AWS re:Invent supporting NVIDIA Nemotron 2 Nano 9B and NVIDIA Nemotron 2 Nano VL 12B models. This post explores the technical characteristics of the NVIDIA Nemotron 3 Nano model and discusses potential application use cases. Additionally, it provides technical guidance to help you get started using this model for your generative AI applications within the Amazon Bedrock environment.

In this post, you will discover how to use Amazon Bedrock's Global cross-Region Inference for Claude models in India. We will guide you through the capabilities of each Claude model variant and how to get started with a code example to help you start building generative AI applications immediately.

In this post, we walk through a multi-developer CI/CD pipeline for Amazon Lex that enables isolated development environments, automated testing, and streamlined deployments. We show you how to set up the solution and share real-world results from teams using this approach.

This post demonstrates how to build custom model parsers for Strands agents when working with LLMs hosted on SageMaker that don't natively support the Bedrock Messages API format. We'll walk through deploying Llama 3.1 with SGLang on SageMaker using awslabs/ml-container-creator, then implementing a custom parser to integrate it with Strands agents.

Organizations find it challenging to implement a secure embedded chat in their applications and can require weeks of development to build authentication, token validation, domain security, and global distribution infrastructure. In this post, we show you how to solve this with a one-click deployment solution to embed the chat agents using the Quick Suite Embedding SDK in enterprise portals.

In this post, we discuss how Amazon Nova demonstrates capabilities in conversational analytics, call classification, and other use cases often relevant to contact center solutions. We examine these capabilities for both single-call and multi-call analytics use cases.

This post explores how Ricoh built a standardized, multi-tenant solution for automated document classification and extraction using the AWS GenAI IDP Accelerator as a foundation, transforming their document processing from a custom-engineering bottleneck into a scalable, repeatable service.

In this post, we explore the virtual try-on capability now available in Amazon Nova Canvas, including sample code to get started quickly and tips to help get the best outputs.

This post details how Lendi Group built their AI-powered Home Loan Guardian using Amazon Bedrock, the challenges they faced, the architecture they implemented, and the significant business outcomes they’ve achieved. Their journey offers valuable insights for organizations that want to use generative AI to transform customer experiences while maintaining the human touch that builds trust and loyalty.

In this post, we show you how to connect Quick Suite with Tines to securely retrieve, analyze, and visualize enterprise data from any security or IT system. We walk through an example that uses a MCP server in Tines to retrieve data from various tools, such as AWS CloudTrail, Okta, and VirusTotal, to remediate security events using Quick Suite.

In this post, we share results from the AWS China Applied Science team's comprehensive evaluation of Nova Forge using a challenging Voice of Customer (VOC) classification task, benchmarked against open-source models.

This post explores how to build an intelligent conversational agent using Amazon Bedrock, LangGraph, and managed MLflow on Amazon SageMaker AI.

In this post, we will show you how to configure Amazon Bedrock Guardrails for efficient performance, implement best practices to protect your applications, and monitor your deployment effectively to maintain the right balance between safety and user experience.

Delivering successful COBOL modernization requires a solution that can reverse engineer deterministically, produce validated and traceable specs, and help those specs flow into any AI-powered coding assistant for the forward engineering. A successful modernization requires both reverse engineering and forward engineering. Learn more about COBOL in this post.

In this post, we explore reinforcement fine-tuning (RFT) for Amazon Nova models, which can be a powerful customization technique that learns through evaluation rather than imitation. We'll cover how RFT works, when to use it versus supervised fine-tuning, real-world applications from code generation to customer service, and implementation options ranging from fully managed Amazon Bedrock to multi-turn agentic workflows with Nova Forge. You'll also learn practical guidance on data preparation, reward function design, and best practices for achieving optimal results.

AWS recently released significant updates to the Large Model Inference (LMI) container, delivering comprehensive performance improvements, expanded model support, and streamlined deployment capabilities for customers hosting LLMs on AWS. These releases focus on reducing operational complexity while delivering measurable performance gains across popular model architectures.

In this post, we explain how we implemented multi-LoRA inference for Mixture of Experts (MoE) models in vLLM, describe the kernel-level optimizations we performed, and show you how you can benefit from this work. We use GPT-OSS 20B as our primary example throughout this post.

This post demonstrates how to quickly deploy a production-ready event assistant using the components of Amazon Bedrock AgentCore. We'll build an intelligent companion that remembers attendee preferences and builds personalized experiences over time, while Amazon Bedrock AgentCore handles the heavy lifting of production deployment: Amazon Bedrock AgentCore Memory for maintaining both conversation context and long-term preferences without custom storage solutions, Amazon Bedrock AgentCore Identity for secure multi-IDP authentication, and Amazon Bedrock AgentCore Runtime for serverless scaling and session isolation. We will also use Amazon Bedrock Knowledge Bases for managed RAG and event data retrieval.

In this post, we show you how to build a comprehensive photo search system using the AWS Cloud Development Kit (AWS CDK) that integrates Amazon Rekognition for face and object detection, Amazon Neptune for relationship mapping, and Amazon Bedrock for AI-powered captioning.

In this post, we demonstrate how to train CodeFu-7B, a specialized 7-billion parameter model for competitive programming, using Group Relative Policy Optimization (GRPO) with veRL, a flexible and efficient training library for large language models (LLMs) that enables straightforward extension of diverse RL algorithms and seamless integration with existing LLM infrastructure, within a distributed Ray cluster managed by SageMaker training jobs. We walk through the complete implementation, covering data preparation, distributed training setup, and comprehensive observability, showcasing how this unified approach delivers both computational scale and developer experience for sophisticated RL training workloads.

This post explores the implementation of Dottxt’s Outlines framework as a practical approach to implementing structured outputs using AWS Marketplace in Amazon SageMaker.

In this post, we are exciting to announce availability of Global CRIS for customers in Thailand, Malaysia, Singapore, Indonesia, and Taiwan and give a walkthrough of technical implementation steps, and cover quota management best practices to maximize the value of your AI Inference deployments. We also provide guidance on best practices for production deployments.

We’re excited to announce the availability of Anthropic’s Claude Opus 4.6, Claude Sonnet 4.6, Claude Opus 4.5, Claude Sonnet 4.5, and Claude Haiku 4.5 through Amazon Bedrock global cross-Region inference for customers operating in the Middle East. In this post, we guide you through the capabilities of each Anthropic Claude model variant, the key advantages of global cross-Region inference including improved resilience, real-world use cases you can implement, and a code example to help you start building generative AI applications immediately.

In this post, we examine how Bedrock Robotics tackles this challenge. By joining the AWS Physical AI Fellowship, the startup partnered with the AWS Generative AI Innovation Center to apply vision-language models that analyze construction video footage, extract operational details, and generate labeled training datasets at scale, to improve data preparation for autonomous construction equipment.

In this post, we explore how Sonrai, a life sciences AI company, partnered with AWS to build a robust MLOps framework using Amazon SageMaker AI that addresses these challenges while maintaining the traceability and reproducibility required in regulated environments.

In this blog post, we demonstrate how Hexagon collaborated with Amazon Web Services to scale their AI model production by pretraining state-of-the-art segmentation models, using the model training infrastructure of Amazon SageMaker HyperPod.

Hugging Face smolagents is an open source Python library designed to make it straightforward to build and run agents using a few lines of code. We will show you how to build an agentic AI solution by integrating Hugging Face smolagents with Amazon Web Services (AWS) managed services. You'll learn how to deploy a healthcare AI agent that demonstrates multi-model deployment options, vector-enhanced knowledge retrieval, and clinical decision support capabilities.

In 2025, Amazon SageMaker AI saw dramatic improvements to core infrastructure offerings along four dimensions: capacity, price performance, observability, and usability. In this series of posts, we discuss these various improvements and their benefits. In Part 1, we discuss capacity improvements with the launch of Flexible Training Plans. We also describe improvements to price performance for inference workloads. In Part 2, we discuss enhancements made to observability, model customization, and model hosting.

In 2025, Amazon SageMaker AI made several improvements designed to help you train, tune, and host generative AI workloads. In Part 1 of this series, we discussed Flexible Training Plans and price performance improvements made to inference components. In this post, we discuss enhancements made to observability, model customization, and model hosting. These improvements facilitate a whole new class of customer use cases to be hosted on SageMaker AI.

In this post, you’ll use a six-step checklist to build a new MCP server or validate and adjust an existing MCP server for Amazon Quick integration. The Amazon Quick User Guide describes the MCP client behavior and constraints. This is a “How to” guide for detailed implementation required by 3P partners to integrate with Amazon Quick with MCP.

In this post, we explain how you can use the Flyte Python SDK to orchestrate and scale AI/ML workflows. We explore how the Union.ai 2.0 system enables deployment of Flyte on Amazon Elastic Kubernetes Service (Amazon EKS), integrating seamlessly with AWS services like Amazon Simple Storage Service (Amazon S3), Amazon Aurora, AWS Identity and Access Management (IAM), and Amazon CloudWatch. We explore the solution through an AI workflow example, using the new Amazon S3 Vectors service.

In this blog post, we will guide you through establishing data source connectivity between Amazon Quick Sight and Snowflake through secure key pair authentication.

In this post, we demonstrate how to build unified intelligence systems using Amazon Bedrock AgentCore through our real-world implementation of the Customer Agent and Knowledge Engine (CAKE).

In this post, we present a comprehensive evaluation framework for Amazon agentic AI systems that addresses the complexity of agentic AI applications at Amazon through two core components: a generic evaluation workflow that standardizes assessment procedures across diverse agent implementations, and an agent evaluation library that provides systematic measurements and metrics in Amazon Bedrock AgentCore Evaluations, along with Amazon use case-specific evaluation approaches and metrics.

The release of Anthropic Claude Sonnet 4.5 in the AWS GovCloud (US) Region introduces a straightforward on-ramp for AI-assisted development for workloads with regulatory compliance requirements. In this post, we explore how to combine Claude Sonnet 4.5 on Amazon Bedrock in AWS GovCloud (US) with Claude Code, an agentic coding assistant released by Anthropic. This […]

Today, we are announcing three new capabilities that address these requirements: proxy configuration, browser profiles, and browser extensions. Together, these features give you fine-grained control over how your AI agents interact with the web. This post will walk through each capability with configuration examples and practical use cases to help you get started.

In this post, we show how to create an AI-powered recruitment system using Amazon Bedrock, Amazon Bedrock Knowledge Bases, AWS Lambda, and other AWS services to enhance job description creation, candidate communication, and interview preparation while maintaining human oversight.

In this post, we provide you with a comprehensive approach to achieve this. First, we introduce a context message strategy that maintains continuous communication between servers and clients during extended operations. Next, we develop an asynchronous task management framework that allows your AI agents to initiate long-running processes without blocking other operations. Finally, we demonstrate how to bring these strategies together with Amazon Bedrock AgentCore and Strands Agents to build production-ready AI agents that can handle complex, time-intensive operations reliably.

Today we’re excited to announce that the NVIDIA Nemotron 3 Nano 30B model with 3B active parameters is now generally available in the Amazon SageMaker JumpStart model catalog. You can accelerate innovation and deliver tangible business value with Nemotron 3 Nano on Amazon Web Services (AWS) without having to manage model deployment complexities. You can power your generative AI applications with Nemotron capabilities using the managed deployment capabilities offered by SageMaker JumpStart.

This post shows you how to implement robust error handling strategies that can help improve application reliability and user experience when using Amazon Bedrock. We'll dive deep into strategies for optimizing performances for the application with these errors. Whether this is for a fairly new application or matured AI application, in this post you will be able to find the practical guidelines to operate with on these errors.

This post shows you how to implement intelligent notification filtering using Amazon Bedrock and its gen-AI capabilities. You'll learn model selection strategies, cost optimization techniques, and architectural patterns for deploying gen-AI at IoT scale, based on Swann Communications deployment across millions of devices.

LinqAlpha is a Boston-based multi-agent AI system built specifically for institutional investors. The system supports and streamlines agentic workflows across company screening, primer generation, stock price catalyst mapping, and now, pressure-testing investment ideas through a new AI agent called Devil’s Advocate. In this post, we share how LinqAlpha uses Amazon Bedrock to build and scale Devil’s Advocate.

In this post, we discuss how Amazon Nova in Amazon Bedrock can be used to implement an AI-powered image recognition solution that automates the detection and validation of module components, significantly reducing manual verification efforts and improving accuracy.

Iberdrola, one of the world’s largest utility companies, has embraced cutting-edge AI technology to revolutionize its IT operations in ServiceNow. Through its partnership with AWS, Iberdrola implemented different agentic architectures using Amazon Bedrock AgentCore, targeting three key areas: optimizing change request validation in the draft phase, enriching incident management with contextual intelligence, and simplifying change model selection using conversational AI. These innovations reduce bottlenecks, help teams accelerate ticket resolution, and deliver consistent and high-quality data handling throughout the organization.

Amazon Nova Sonic delivers real-time, human-like voice conversations through the bidirectional streaming interface. In this post, you learn how Amazon Nova Sonic can solve some of the challenges faced by cascaded approaches, simplify building voice AI agents, and provide natural conversational capabilities. We also provide guidance on when to choose each approach to help you make informed decisions for your voice AI projects.

This blog post dives deeper into the implementation architecture for the Automated Reasoning checks rewriting chatbot.

In this post, we show how this integrated approach transforms enterprise LLM fine-tuning from a complex, resource-intensive challenge into a streamlined, scalable solution for achieving better model performance in domain-specific applications.

Working with the Generative AI Innovation Center, New Relic NOVA (New Relic Omnipresence Virtual Assistant) evolved from a knowledge assistant into a comprehensive productivity engine. We explore the technical architecture, development journey, and key lessons learned in building an enterprise-grade AI solution that delivers measurable productivity gains at scale.

In this post, you will learn how to deploy Fullstack AgentCore Solution Template (FAST) to your Amazon Web Services (AWS) account, understand its architecture, and see how to extend it for your requirements. You will learn how to build your own agent while FAST handles authentication, infrastructure as code (IaC), deployment pipelines, and service integration.

This post walks through how agent-to-agent collaboration on Amazon Bedrock works in practice, using Amazon Nova 2 Lite for planning and Amazon Nova Act for browser interaction, to turn a fragile single-agent setup into a predictable multi-agent system.

Today, we're announcing structured outputs on Amazon Bedrock—a capability that fundamentally transforms how you can obtain validated JSON responses from foundation models through constrained decoding for schema compliance. In this post, we explore the challenges of traditional JSON generation and how structured outputs solves them. We cover the two core mechanisms—JSON Schema output format and strict tool use—along with implementation details, best practices, and practical code examples.

In this post, we demonstrate how to use the CLI and the SDK to create and manage SageMaker HyperPod clusters in your AWS account. We walk through a practical example and dive deeper into the user workflow and parameter choices.

In this post, we explore the Amazon Nova rubric-based judge feature: what a rubric-based judge is, how the judge is trained, what metrics to consider, and how to calibrate the judge. We chare notebook code of the Amazon Nova rubric-based LLM-as-a-judge methodology to evaluate and compare the outputs of two different LLMs using SageMaker training jobs.

Associa collaborated with the AWS Generative AI Innovation Center to build a generative AI-powered document classification system aligning with Associa’s long-term vision of using generative AI to achieve operational efficiencies in document management. The solution automatically categorizes incoming documents with high accuracy, processes documents efficiently, and provides substantial cost savings while maintaining operational excellence. The document classification system, developed using the Generative AI Intelligent Document Processing (GenAI IDP) Accelerator, is designed to integrate seamlessly into existing workflows. It revolutionizes how employees interact with document management systems by reducing the time spent on manual classification tasks.

In this post, you will learn how to configure and use Amazon Nova Multimodal Embeddings for media asset search systems, product discovery experiences, and document retrieval applications.

Building upon our earlier work of marketing campaign image generation using Amazon Nova foundation models, in this post, we demonstrate how to enhance image generation by learning from previous marketing campaigns. We explore how to integrate Amazon Bedrock, AWS Lambda, and Amazon OpenSearch Serverless to create an advanced image generation system that uses reference campaigns to maintain brand guidelines, deliver consistent content, and enhance the effectiveness and efficiency of new campaign creation.

BGL is a leading provider of self-managed superannuation fund (SMSF) administration solutions that help individuals manage the complex compliance and reporting of their own or a client’s retirement savings, serving over 12,700 businesses across 15 countries. In this blog post, we explore how BGL built its production-ready AI agent using Claude Agent SDK and Amazon Bedrock AgentCore.
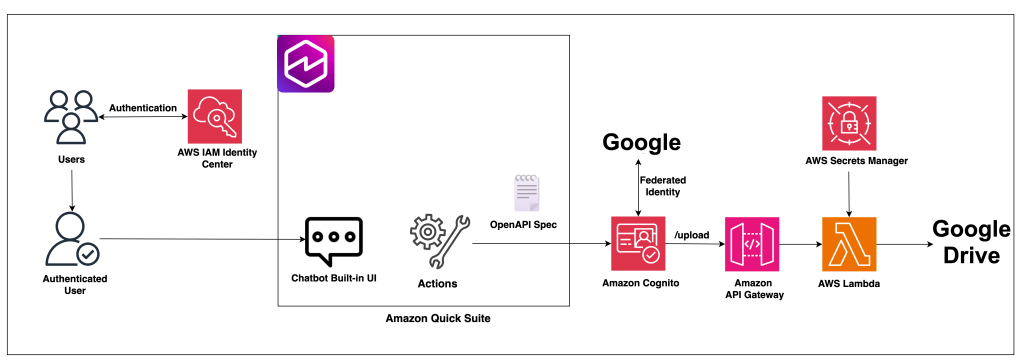
In this post, we demonstrate how to build a secure file upload solution by integrating Google Drive with Amazon Quick Suite custom connectors using Amazon API Gateway and AWS Lambda.

This post explores nine essential best practices for building enterprise AI agents using Amazon Bedrock AgentCore. Amazon Bedrock AgentCore is an agentic platform that provides the services you need to create, deploy, and manage AI agents at scale. In this post, we cover everything from initial scoping to organizational scaling, with practical guidance that you can apply immediately.

On November 21, 2025, Amazon SageMaker introduced a built-in data agent within Amazon SageMaker Unified Studio that transforms large-scale data analysis. In this post, we demonstrate, through a detailed case study of an epidemiologist conducting clinical cohort analysis, how SageMaker Data Agent can help reduce weeks of data preparation into days, and days of analysis development into hours—ultimately accelerating the path from clinical questions to research conclusions.

In this post, we illustrate how Clarus Care, a healthcare contact center solutions provider, worked with the AWS Generative AI Innovation Center (GenAIIC) team to develop a generative AI-powered contact center prototype. This solution enables conversational interaction and multi-intent resolution through an automated voicebot and chat interface. It also incorporates a scalable service model to support growth, human transfer capabilities--when requested or for urgent cases--and an analytics pipeline for performance insights.

This post explores how you can use Amazon S3-based templates to simplify ModelOps workflows, walk through the key benefits compared to using Service Catalog approaches, and demonstrates how to create a custom ModelOps solution that integrates with GitHub and GitHub Actions—giving your team one-click provisioning of a fully functional ML environment.

In this post, we walk through how global cross-Region inference routes requests and where your data resides, then show you how to configure the required AWS Identity and Access Management (IAM) permissions and invoke Claude 4.5 models using the global inference profile Amazon Resource Name (ARN). We also cover how to request quota increases for your workload. By the end, you'll have a working implementation of global cross-Region inference in af-south-1.

The agent-based approach we present is applicable to any type of enterprise content, from product documentation and knowledge bases to marketing materials and technical specifications. To demonstrate these concepts in action, we walk through a practical example of reviewing blog content for technical accuracy. These patterns and techniques can be directly adapted to various content review needs by adjusting the agent configurations, tools, and verification sources.

In this post, we walk you through Pushpay's journey in building this solution and explore how Pushpay used Amazon Bedrock to create a custom generative AI evaluation framework for continuous quality assurance and establishing rapid iteration feedback loops on AWS.

This blog post demonstrates how to build an intelligent contract management solution using Amazon Quick Suite as your primary contract management solution, augmented with Amazon Bedrock AgentCore for advanced multi-agent capabilities.

In this post, we discuss how to use AppSync Events as the foundation of a capable, serverless, AI gateway architecture. We explore how it integrates with AWS services for comprehensive coverage of the capabilities offered in AI gateway architectures. Finally, we get you started on your journey with sample code you can launch in your account and begin building.

This blog post describes how Totogi automates change request processing by partnering with the AWS Generative AI Innovation Center and using the rapid innovation capabilities of Amazon Bedrock.

Amazon Bedrock AgentCore services are now being supported by various IaC frameworks such as AWS Cloud Development Kit (AWS CDK), Terraform and AWS CloudFormation Templates. This integration brings the power of IaC directly to AgentCore so developers can provision, configure, and manage their AI agent infrastructure. In this post, we use CloudFormation templates to build an end-to-end application for a weather activity planner.

In this post, we demonstrate how the Amazon Catalog Team built a self-learning system that continuously improves accuracy while reducing costs at scale using Amazon Bedrock.

PDI Technologies is a global leader in the convenience retail and petroleum wholesale industries. In this post, we walk through the PDI Intelligence Query (PDIQ) process flow and architecture, focusing on the implementation details and the business outcomes it has helped PDI achieve.

In this post, we demonstrate how CLICKFORCE used AWS services to build Lumos and transform advertising industry analysis from weeks-long manual work into an automated, one-hour process.

This blog post explains how TR's Platform Engineering team, a geographically distributed unit overseeing TR's service availability, boosted its operational productivity by transitioning from manual to an automated agentic system using Amazon Bedrock AgentCore.

In this post, we walk you through the complete architecture to structure and store episodes, discuss the reflection module, and share compelling benchmarks that demonstrate significant improvements in agent task success rates.

In this post, we show how bunq upgraded Finn, its in-house generative AI assistant, using Amazon Bedrock to transform user support and banking operations to be seamless, in multiple languages and time zones.

In this post, we explore how to build a multi-agent video processing workflow using Strands Agents, Meta's Llama 4 models, and Amazon Bedrock to automatically analyze and understand video content through specialized AI agents working in coordination. To showcase the solution, we will use Amazon SageMaker AI to walk you through the code.

In this post, we'll guide you through building multimodal RAG applications. You'll learn how multimodal knowledge bases work, how to choose the right processing strategy based on your content type, and how to configure and implement multimodal retrieval using both the console and code examples.

In this post, we show you how fine-tuning enabled a 33% reduction in dangerous medication errors (Amazon Pharmacy), engineering 80% human effort reduction (Amazon Global Engineering Services), and content quality assessments improving 77% to 96% accuracy (Amazon A+). This post details the techniques behind these outcomes: from foundational methods like Supervised Fine-Tuning (SFT) (instruction tuning), and Proximal Policy Optimization (PPO), to Direct Preference Optimization (DPO) for human alignment, to cutting-edge reasoning optimizations such as Grouped-based Reinforcement Learning from Policy Optimization (GRPO), Direct Advantage Policy Optimization (DAPO), and Group Sequence Policy Optimization (GSPO) purpose-built for agentic systems.

The AWS AI League, launched by Amazon Web Services (AWS), expanded its reach to the Association of Southeast Asian Nations (ASEAN) last year, welcoming student participants from Singapore, Indonesia, Malaysia, Thailand, Vietnam, and the Philippines. In this blog post, you’ll hear directly from the AWS AI League champion, Blix D. Foryasen, as he shares his reflection on the challenges, breakthroughs, and key lessons discovered throughout the competition.

In this post, we demonstrate how to use a GitHub Actions workflow to automate the deployment of AI agents on AgentCore Runtime. This approach delivers a scalable solution with enterprise-level security controls, providing complete continuous integration and delivery (CI/CD) automation.

In this post, we explain how we overcame the limitations of single-agent AI systems through a human-centric approach, implemented structured outputs to significantly reduce hallucinations and built a scalable solution now positioned for expansion across the AMET QA team and later across other QA teams in International Emerging Stores and Payments (IESP) Org.

This post introduces generative AI guided business reporting—with a focus on writing achievements & challenges about your business—providing a smart, practical solution that helps simplify and accelerate internal communication and reporting.

In this post, we demonstrate how you can address these challenges by adding centralized safeguards to a custom multi-provider generative AI gateway using Amazon Bedrock Guardrails.

In this post, we describe how you can use Amazon Nova Multimodal Embeddings to retrieve specific video segments. We also review a real-world use case in which Nova Multimodal Embeddings achieved a recall success rate of 96.7% and a high-precision recall of 73.3% (returning the target content in the top two results) when tested against a library of 170 gaming creative assets. The model also demonstrates strong cross-language capabilities with minimal performance degradation across multiple languages.

In this post, we explore the architecture that AutoScout24 used to build their standardized AI development framework, enabling rapid deployment of secure and scalable AI agents.

This post explores how new serverless model customization capabilities, elastic training, checkpointless training, and serverless MLflow work together to accelerate your AI development from months to days.

In this post, we explore the security considerations and best practices for implementing Amazon Bedrock cross-Region inference profiles. Whether you're building a generative AI application or need to meet specific regional compliance requirements, this guide will help you understand the secure architecture of Amazon Bedrock CRIS and how to properly configure your implementation.

This post is co-written with Sunaina Kavi, AI/ML Product Manager at Omada Health. Omada Health, a longtime innovator in virtual healthcare delivery, launched a new nutrition experience in 2025, featuring OmadaSpark, an AI agent trained with robust clinical input that delivers real-time motivational interviewing and nutrition education. It was built on AWS. OmadaSpark was designed […]
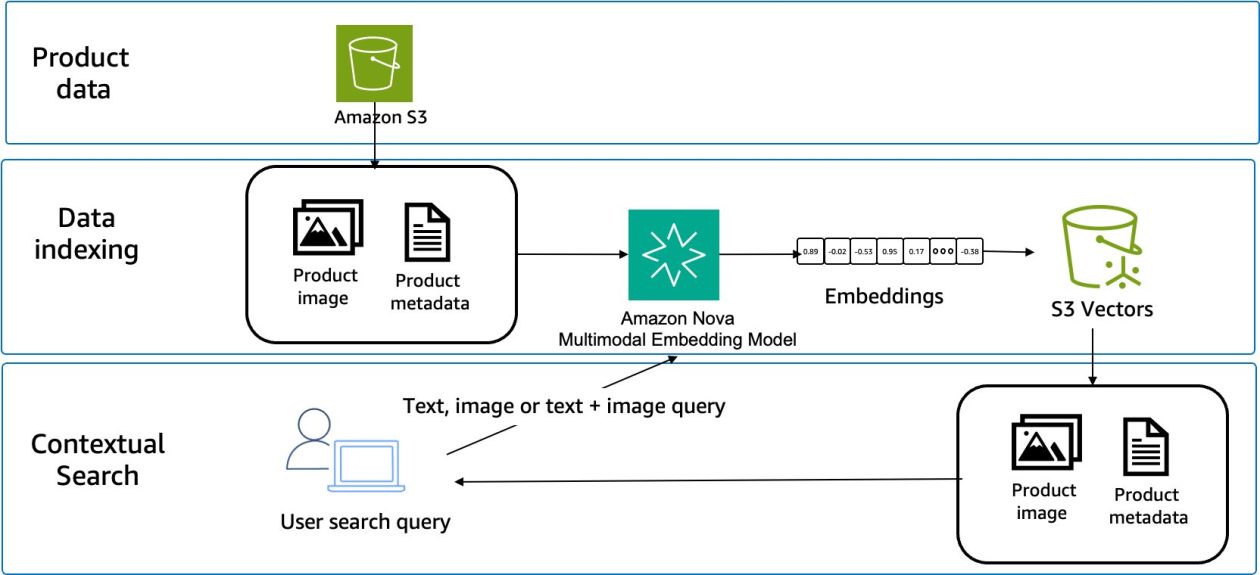
In this post, we explore how Amazon Nova Multimodal Embeddings addresses the challenges of crossmodal search through a practical ecommerce use case. We examine the technical limitations of traditional approaches and demonstrate how Amazon Nova Multimodal Embeddings enables retrieval across text, images, and other modalities. You learn how to implement a crossmodal search system by generating embeddings, handling queries, and measuring performance. We provide working code examples and share how to add these capabilities to your applications.

Quantized models can be seamlessly deployed on Amazon SageMaker AI using a few lines of code. In this post, we explore why quantization matters—how it enables lower-cost inference, supports deployment on resource-constrained hardware, and reduces both the financial and environmental impact of modern LLMs, while preserving most of their original performance. We also take a deep dive into the principles behind PTQ and demonstrate how to quantize the model of your choice and deploy it on Amazon SageMaker.
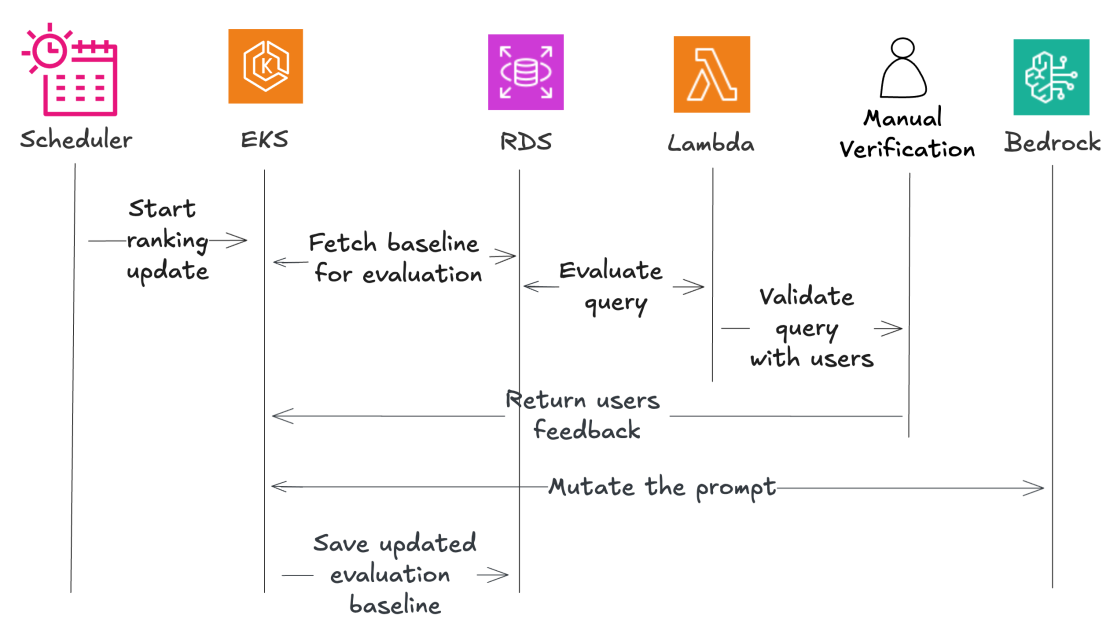
Beekeeper’s automated leaderboard approach and human feedback loop system for dynamic LLM and prompt pair selection addresses the key challenges organizations face in navigating the rapidly evolving landscape of language models.

This post, developed through a strategic scientific partnership between AWS and the Instituto de Ciência e Tecnologia Itaú (ICTi), P&D hub maintained by Itaú Unibanco, the largest private bank in Latin America, explores the technical aspects of sentiment analysis for both text and audio. We present experiments comparing multiple machine learning (ML) models and services, discuss the trade-offs and pitfalls of each approach, and highlight how AWS services can be orchestrated to build robust, end-to-end solutions. We also offer insights into potential future directions, including more advanced prompt engineering for large language models (LLMs) and expanding the scope of audio-based analysis to capture emotional cues that text data alone might miss.

This post provides a detailed architectural overview of how TrueLook built its AI-powered safety monitoring system using SageMaker AI, highlighting key technical decisions, pipeline design patterns, and MLOps best practices. You will gain valuable insights into designing scalable computer vision solutions on AWS, particularly around model training workflows, automated pipeline creation, and production deployment strategies for real-time inference.
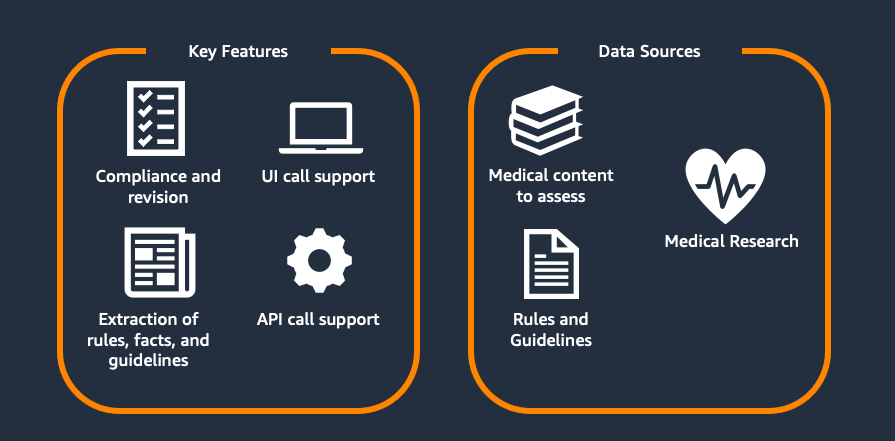
This two-part series explores Flo Health's journey with generative AI for medical content verification. Part 1 examines our proof of concept (PoC), including the initial solution, capabilities, and early results. Part 2 covers focusing on scaling challenges and real-world implementation. Each article stands alone while collectively showing how AI transforms medical content management at scale.

This post shows an automated PII detection and redaction solution using Amazon Bedrock Data Automation and Amazon Bedrock Guardrails through a use case of processing text and image content in high volumes of incoming emails and attachments. The solution features a complete email processing workflow with a React-based user interface for authorized personnel to more securely manage and review redacted email communications and attachments. We walk through the step-by-step solution implementation procedures used to deploy this solution. Finally, we discuss the solution benefits, including operational efficiency, scalability, security and compliance, and adaptability.

Observe.ai developed the One Load Audit Framework (OLAF), which integrates with SageMaker to identify bottlenecks and performance issues in ML services, offering latency and throughput measurements under both static and dynamic data loads. In this blog post, you will learn how to use the OLAF utility to test and validate your SageMaker endpoint.

This post shows you how to migrate your self-managed MLflow tracking server to a MLflow App – a serverless tracking server on SageMaker AI that automatically scales resources based on demand while removing server patching and storage management tasks at no cost. Learn how to use the MLflow Export Import tool to transfer your experiments, runs, models, and other MLflow resources, including instructions to validate your migration's success.

This post demonstrates how to solve this challenge by building an AI-powered website assistant using Amazon Bedrock and Amazon Bedrock Knowledge Bases.

In this post, we explore how to programmatically create an IDP solution that uses Strands SDK, Amazon Bedrock AgentCore, Amazon Bedrock Knowledge Base, and Bedrock Data Automation (BDA). This solution is provided through a Jupyter notebook that enables users to upload multi-modal business documents and extract insights using BDA as a parser to retrieve relevant chunks and augment a prompt to a foundational model (FM).

Enterprise organizations increasingly rely on web-based applications for critical business processes, yet many workflows remain manually intensive, creating operational inefficiencies and compliance risks. Despite significant technology investments, knowledge workers routinely navigate between eight to twelve different web applications during standard workflows, constantly switching contexts and manually transferring information between systems. Data entry and validation tasks […]

In this post, we explore how agentic QA automation addresses these challenges and walk through a practical example using Amazon Bedrock AgentCore Browser and Amazon Nova Act to automate testing for a sample retail application.

In this post, we demonstrate how to optimize large language model (LLM) inference on Amazon SageMaker AI using BentoML's LLM-Optimizer to systematically identify the best serving configurations for your workload.

In this post, we explore how Mantle, Amazon's next-generation inference engine for Amazon Bedrock, implements a zero operator access (ZOA) design that eliminates any technical means for AWS operators to access customer data.

In this post, we explore the new AWS AI League challenges and how they are transforming how organizations approach AI development. The grand finale at AWS re:Invent 2025 was an exciting showcase of their ingenuity and skills.

In this post, we demonstrate how to use Foundation Models (FMs) from Amazon Bedrock and the newly launched Amazon Bedrock AgentCore alongside W&B Weave to help build, evaluate, and monitor enterprise AI solutions. We cover the complete development lifecycle from tracking individual FM calls to monitoring complex agent workflows in production.

In this post, we explore how Qbtech streamlined their machine learning (ML) workflow using Amazon SageMaker AI, a fully managed service to build, train and deploy ML models, and AWS Glue, a serverless service that makes data integration simpler, faster, and more cost effective. This new solution reduced their feature engineering time from weeks to hours, while maintaining the high clinical standards required by healthcare providers.

In this post, the first of a series of three, we focus on how you can use Amazon Nova to streamline, simplify, and accelerate marketing campaign creation through generative AI. We show how Bancolombia, one of Colombia’s largest banks, is experimenting with the Amazon Nova models to generate visuals for their marketing campaigns.