
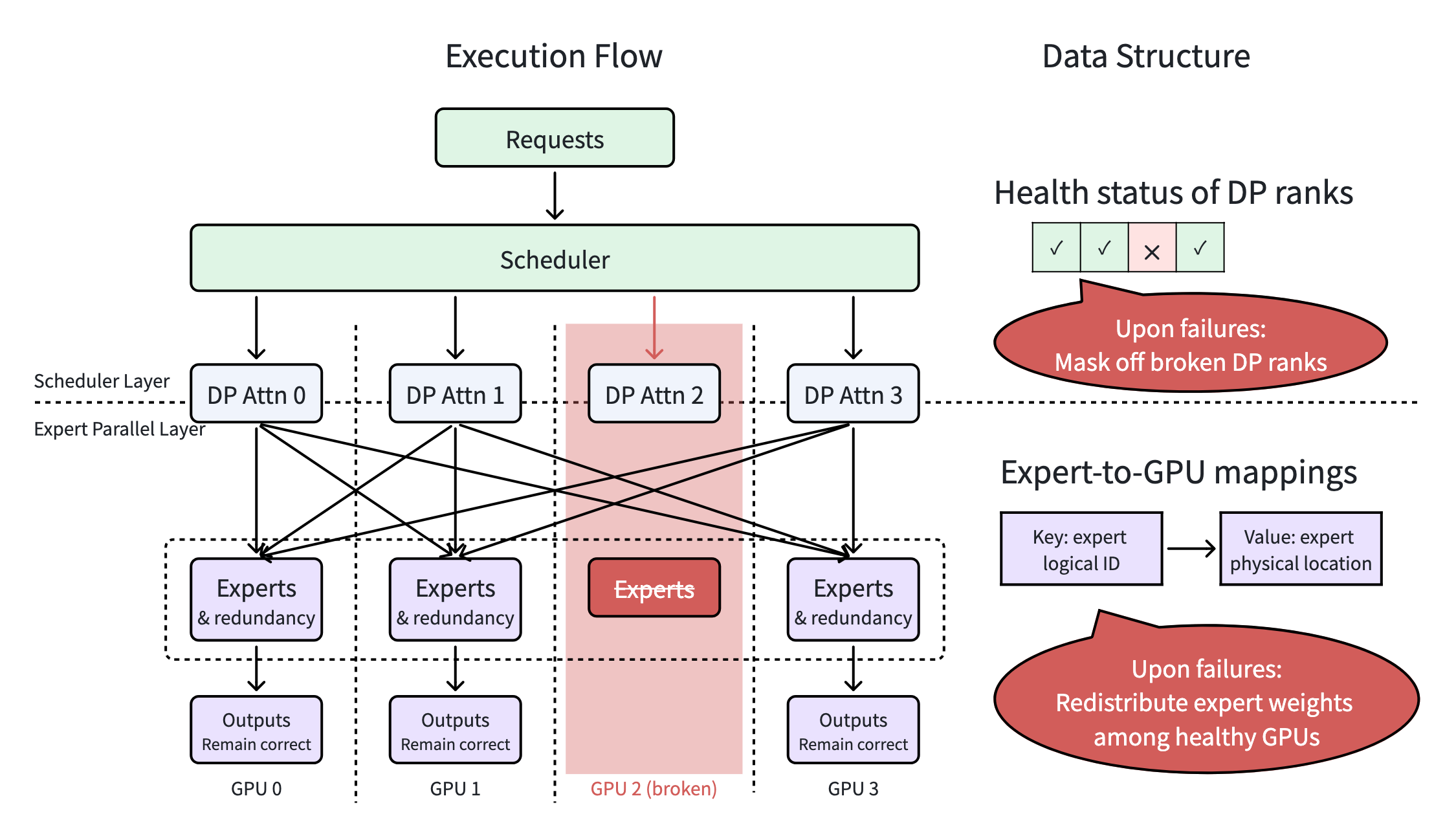
<h2><a id="1-the-problem-the-necessity-and-vulnerability-of-wide-ep" class="anchor" href="#1-the-problem-the-necessity-and-vulnerability-of-wide-ep" aria-hid...

<p>Reinforcement learning (RL) has rapidly become a core stage of modern foundation-model development. While large-scale pretraining remains essential, today...

<p>We are excited to announce that SGLang supports NVIDIA Nemotron 3 Super on Day 0.</p> <p><a href="https://developer.nvidia.com/blog/introducing-nemotron-3...

<p>The SGLang team has worked closely with NVIDIA across <a href="https://lmsys.org/blog/2025-05-05-large-scale-ep/">multiple GPU generations</a> to unlock s...

<h2><a id="tldr" class="anchor" href="#tldr" aria-hidden="true"><svg aria-hidden="true" class="octicon octicon-link" height="16" version="1.1" viewbox="0 0 1...

<p>Following our <a href="https://lmsys.org/blog/2026-01-16-sglang-diffusion/">two-month progress update</a>, we're excited to share a deeper dive into the a...

<h2><a id="1-introduction" class="anchor" href="#1-introduction" aria-hidden="true"><svg aria-hidden="true" class="octicon octicon-link" height="16" version=...

<blockquote> <p>💡 <strong>TL;DR:</strong></p> <p>Inspired by the Kimi K2 team, the SGLang RL team successfully landed an INT4 <strong>Quantization-Aware Tra...
<blockquote> <p>💡 <strong>TL;DR:</strong></p> <p>Inspired by the Kimi K2 team, the SGLang RL team successfully landed an INT4 <strong>Quantization-Aware Tra...

<h2><a id="tldr" class="anchor" href="#tldr" aria-hidden="true"><svg aria-hidden="true" class="octicon octicon-link" height="16" version="1.1" viewbox="0 0 1...
<p>Since its release in early Nov. 2025, <strong>SGLang-Diffusion</strong> has gained significant attention and widespread adoption within the community. We ...

<h2><a id="tldr" class="anchor" href="#tldr" aria-hidden="true"><svg aria-hidden="true" class="octicon octicon-link" height="16" version="1.1" viewbox="0 0 1...

<h2><a id="tldr" class="anchor" href="#tldr" aria-hidden="true"><svg aria-hidden="true" class="octicon octicon-link" height="16" version="1.1" viewbox="0 0 1...

<h2><a id="tldr" class="anchor" href="#tldr" aria-hidden="true"><svg aria-hidden="true" class="octicon octicon-link" height="16" version="1.1" viewbox="0 0 1...

<h2><a id="tldr" class="anchor" href="#tldr" aria-hidden="true"><svg aria-hidden="true" class="octicon octicon-link" height="16" version="1.1" viewbox="0 0 1...
<p>We're excited to introduce <strong>Mini-SGLang</strong>, a lightweight yet high-performance inference framework for Large Language Models (LLMs). Derived ...

<h2><a id="introduction" class="anchor" href="#introduction" aria-hidden="true"><svg aria-hidden="true" class="octicon octicon-link" height="16" version="1.1...

<p>We are excited to announce that SGLang supports the latest highly efficient NVIDIA Nemotron 3 Nano model on Day 0!</p> <p>Nemotron 3 Nano, part of the new...

<h2><a id="tldr" class="anchor" href="#tldr" aria-hidden="true"><svg aria-hidden="true" class="octicon octicon-link" height="16" version="1.1" viewbox="0 0 1...
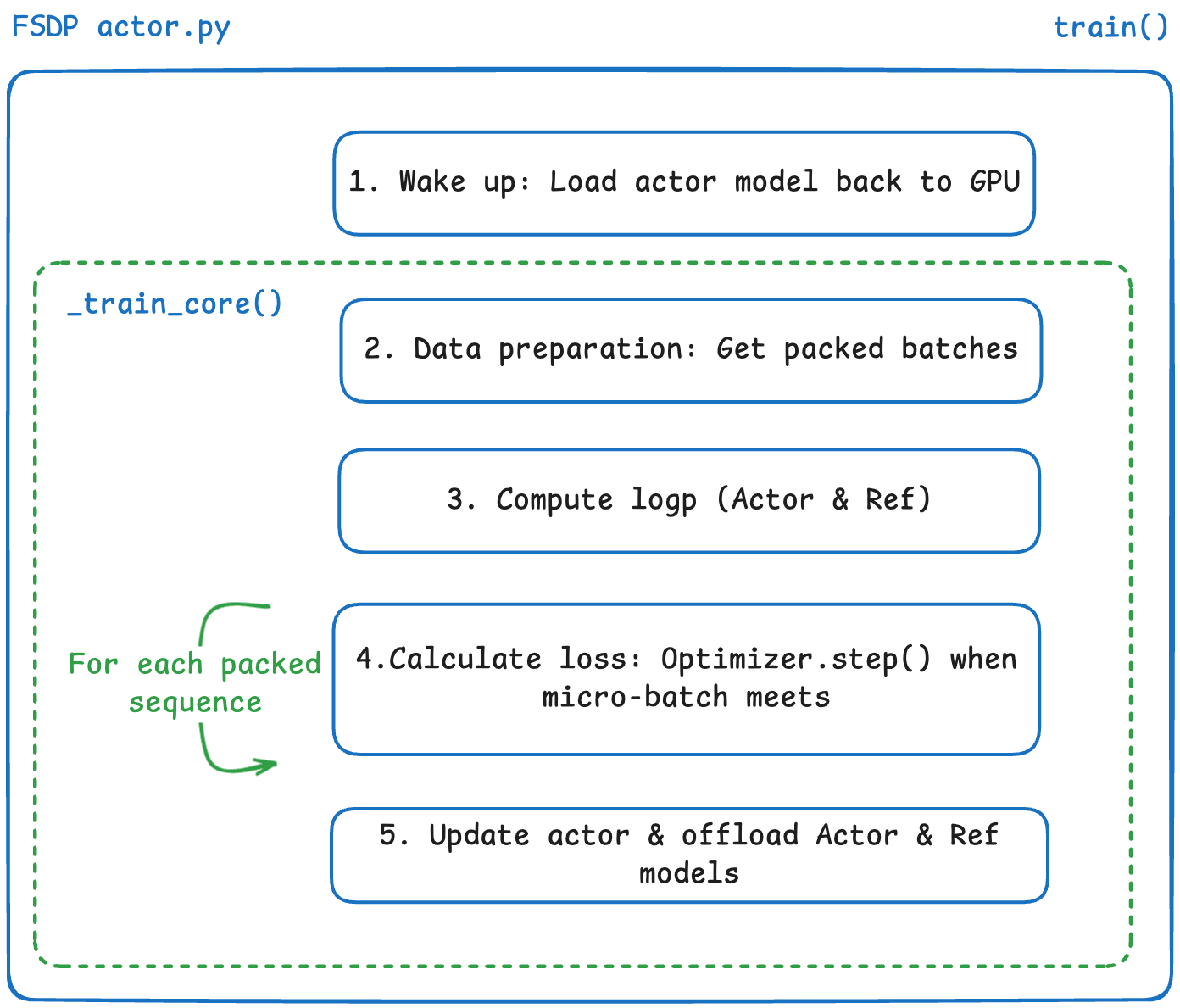
<blockquote> <p><strong>TL;DR:</strong></p> <p><strong>We have added FSDP to <a href="https://github.com/radixark/miles">Miles</a> as a more flexible trainin...
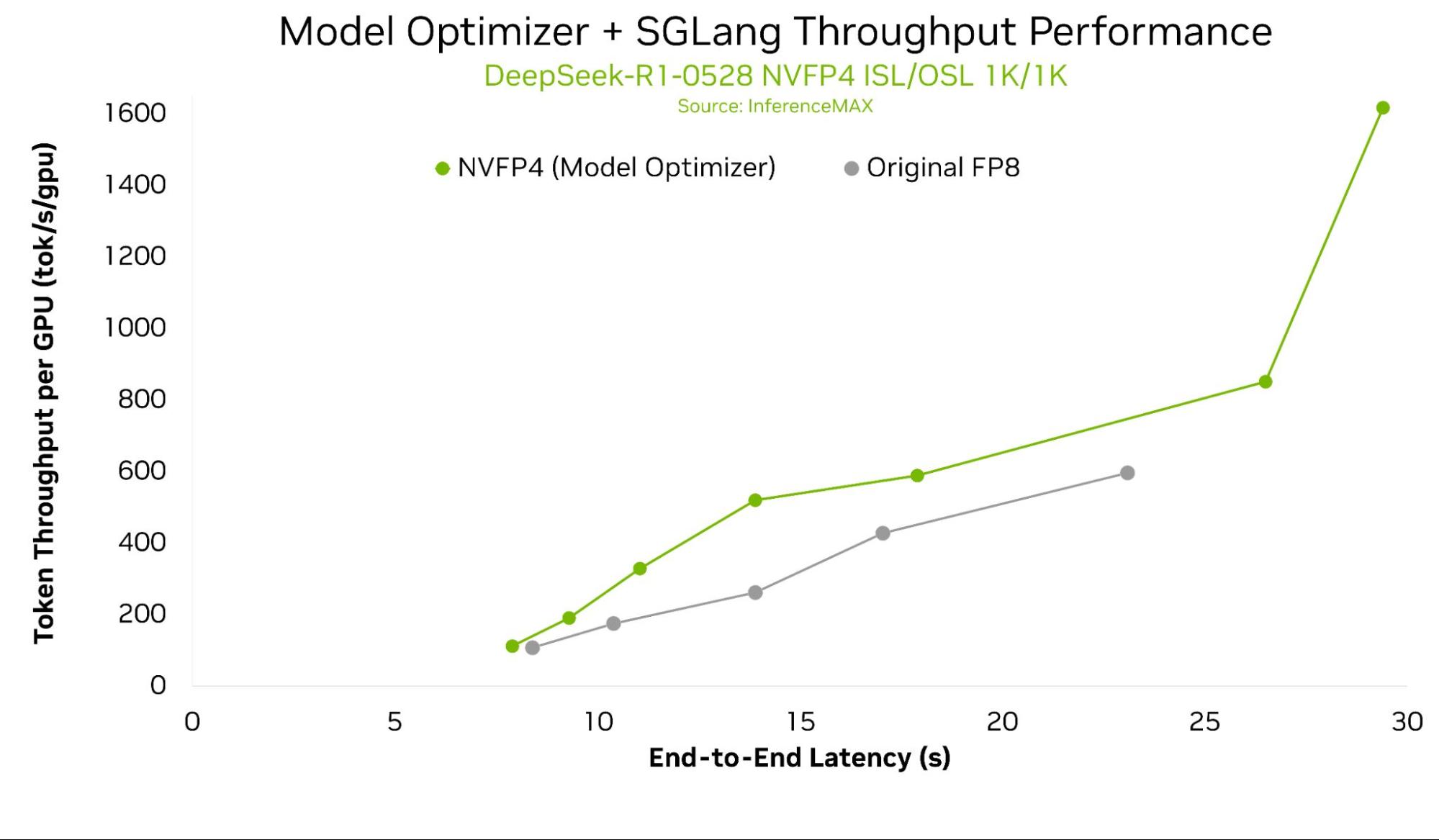
<p>(Updated on Dec 2)</p> <p>We are thrilled to announce a major new feature in SGLang: native support for <a href="https://github.com/NVIDIA/TensorRT-Model-...

<p><strong>TL;DR:</strong> Speculative decoding boosts LLM inference, but traditional methods require a separate, inefficient draft model. Vertex AI utilizes...
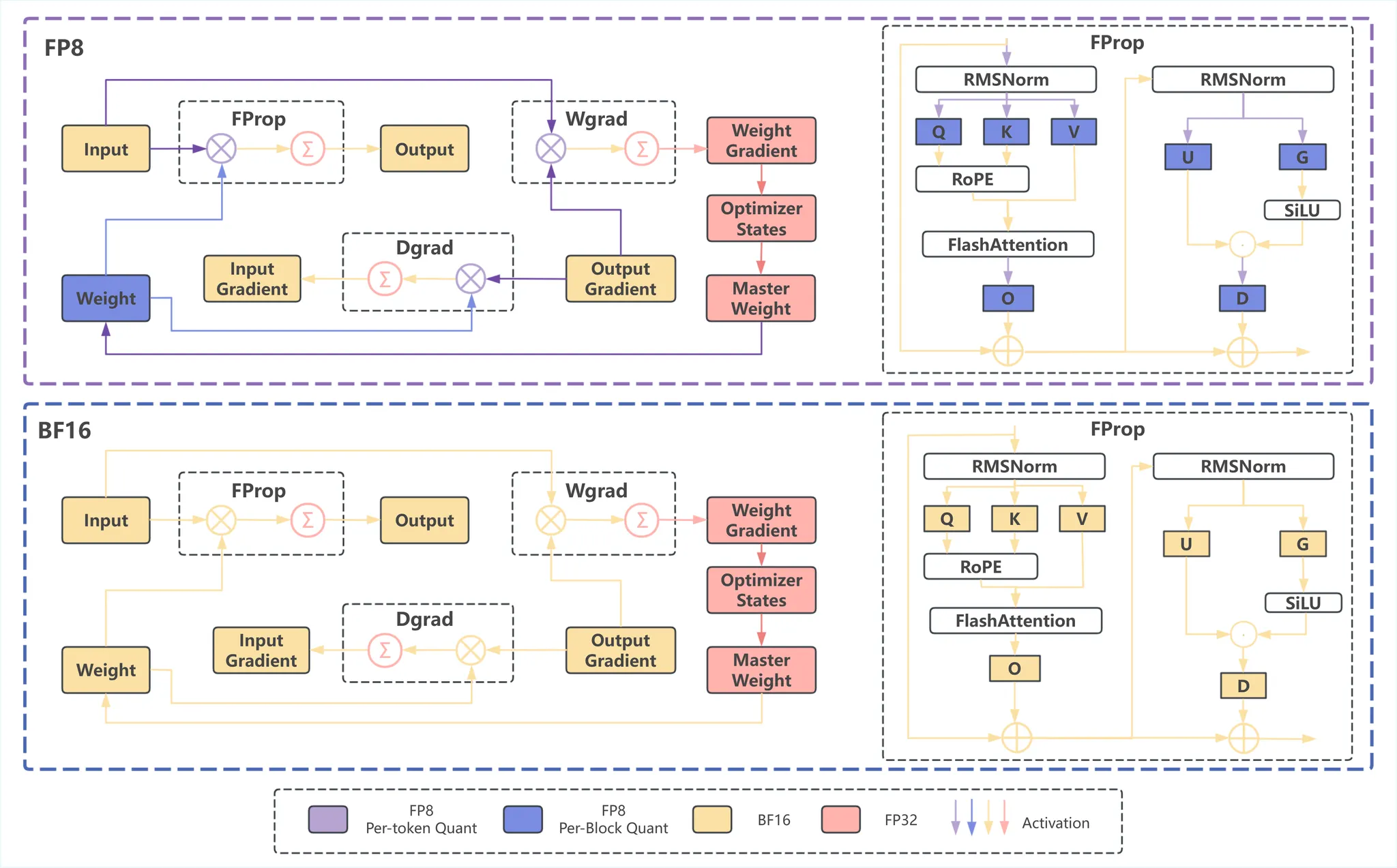
<blockquote> <p>TL;DR: We have implemented fully FP8-based sampling and training in RL. Experiments show that for MoE models, the larger the model, the more ...
<blockquote> <p>TL;DR: We have implemented fully FP8-based sampling and training in RL. Experiments show that for MoE models, the larger the model, the more ...

<p>We're proud to launch the LMSYS Fellowship Program!</p> <p>This year, the program will provide funding to full-time PhD students in the United States who ...

<blockquote> <p><em>A journey of a thousand miles is made one small step at a time.</em></p> </blockquote> <p>We're excited to introduce Miles, an enterprise...

<h2><a id="overview" class="anchor" href="#overview" aria-hidden="true"><svg aria-hidden="true" class="octicon octicon-link" height="16" version="1.1" viewbo...
<p>We are excited to introduce SGLang Diffusion, which brings SGLang's state-of-the-art performance to accelerate image and video generation for diffusion mo...

<p>We are excited to announce day-one support for the new flagship model, MiniMax M2, on SGLang. The MiniMax M2 redefines efficiency for agents: it is a comp...

<p>We are excited to announce day-one support for the new flagship model, MiniMax M2, on SGLang. The MiniMax M2 redefines efficiency for agents: it is a comp...

<p>We’ve got some exciting updates about the <strong>NVIDIA DGX Spark</strong>! In the week following the official launch, we collaborated closely with NVIDI...

<p>We're excited to introduce SGLang-Jax, a state-of-the-art open-source inference engine built entirely on Jax and XLA. It leverages SGLang's high-performan...

<h2><a id="background-hybrid-inference-for-sparse-moe-models" class="anchor" href="#background-hybrid-inference-for-sparse-moe-models" aria-hidden="true"><sv...

<p>The SGLang and NVIDIA teams have a strong track record of collaboration, consistently delivering inference optimizations and system-level improvements to ...

<p>Thanks to NVIDIA’s early access program, we are thrilled to get our hands on the NVIDIA DGX™ Spark. It’s quite an unconventional system, as NVIDIA rarely ...

<p>We are excited to announce that <strong>SGLang supports DeepSeek-V3.2 on Day 0</strong>! According to the DeepSeek <a href="https://github.com/deepseek-ai...
<p>This post highlights our initial efforts to support <strong>a new serving paradigm, PD-Multiplexing, in</strong> <strong>SGLang.</strong> It is designed t...
<h2><a id="introduction" class="anchor" href="#introduction" aria-hidden="true"><svg aria-hidden="true" class="octicon octicon-link" height="16" version="1.1...
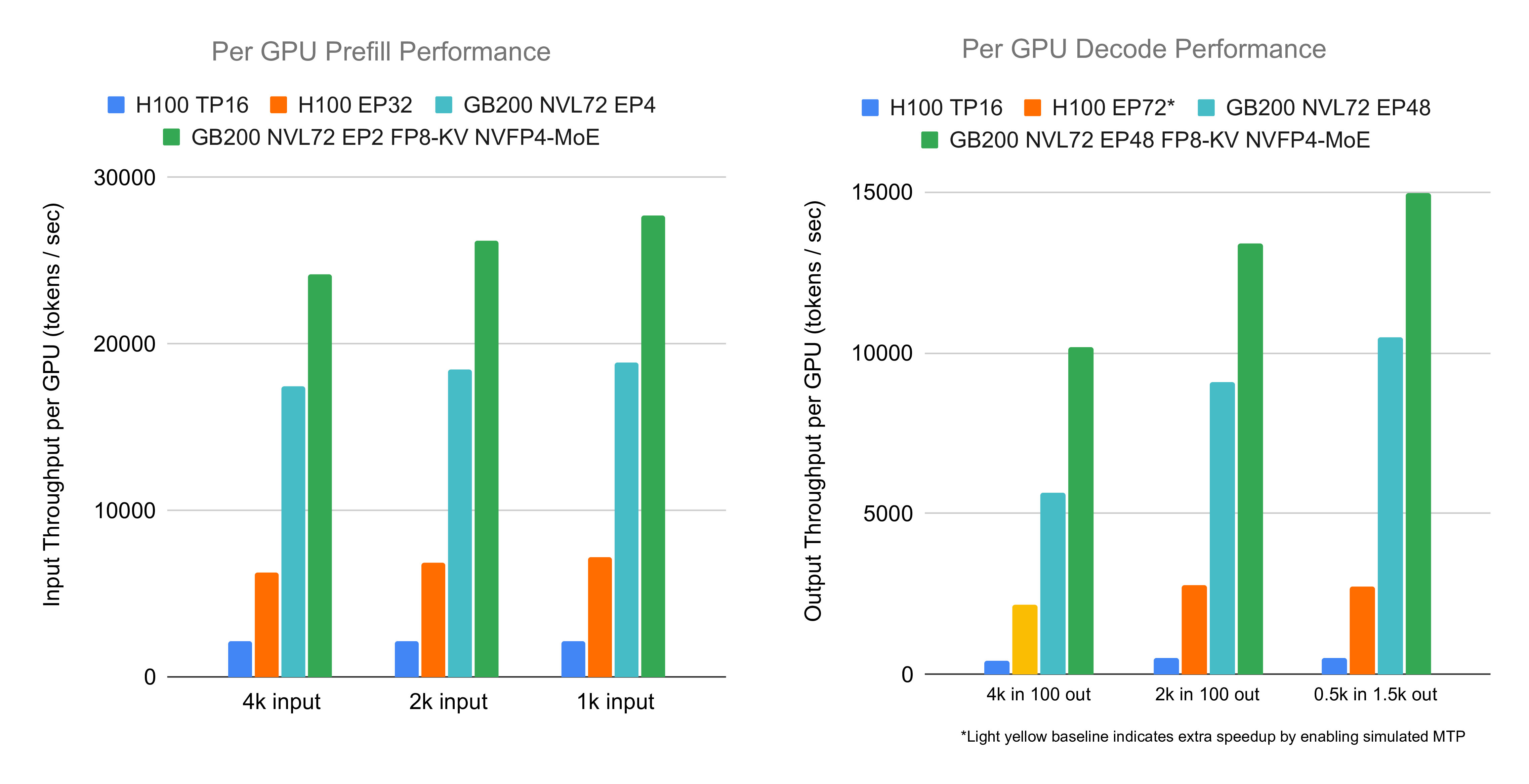
<p>The GB200 NVL72 is one of the most powerful hardware for deep learning. In this blog post, we share our progress to optimize the inference performance of ...
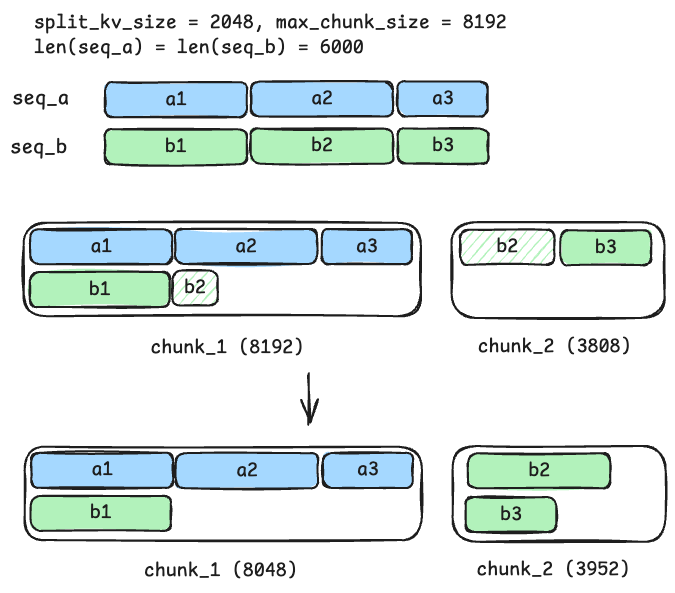
<p>This post highlights our initial efforts to achieve deterministic inference in SGLang. By integrating batch invariant kernels released by Thinking Machine...
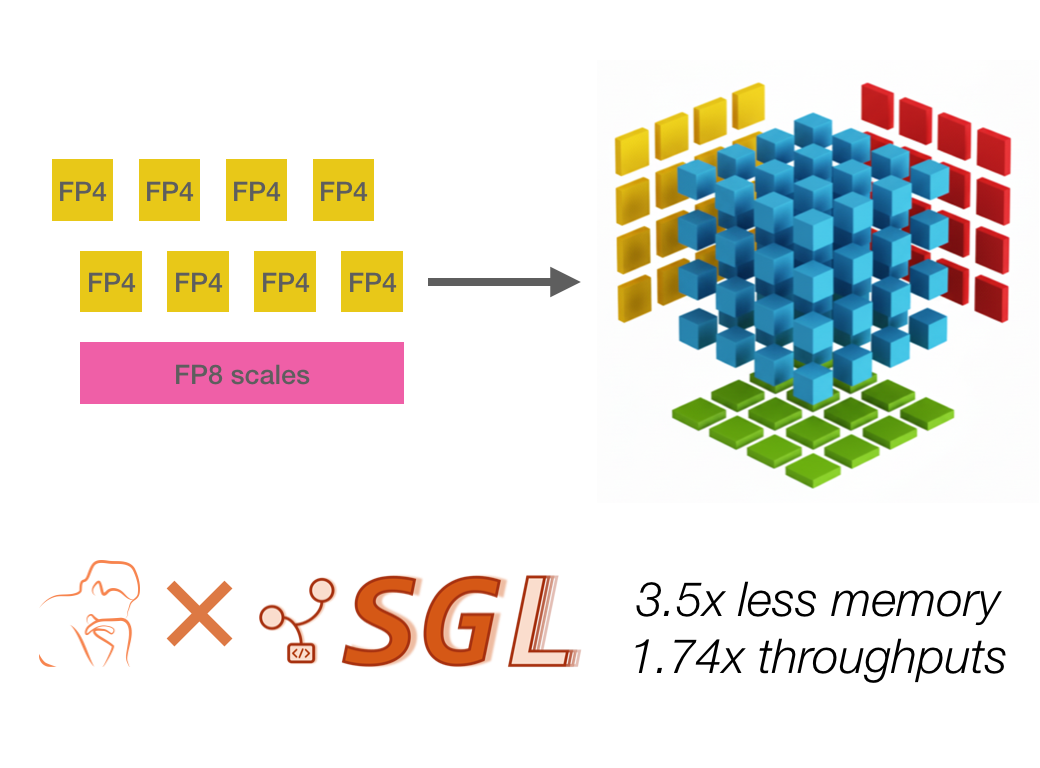
<p>Haohui Mai (CausalFlow.ai), Lei Zhang (AMD)</p> <h2><a id="introduction" class="anchor" href="#introduction" aria-hidden="true"><svg aria-hidden="true" cl...
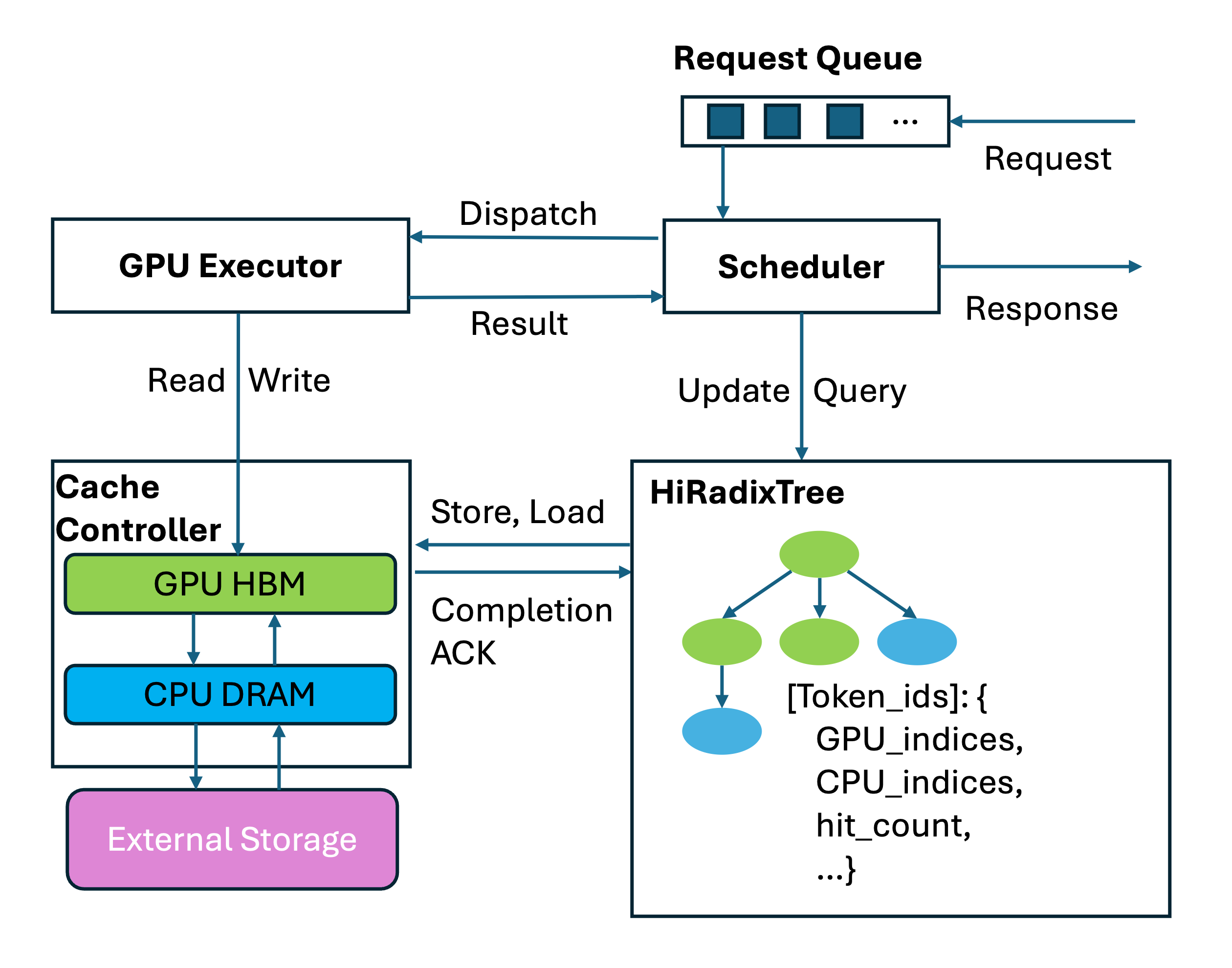
<h2><a id="from-the-community" class="anchor" href="#from-the-community" aria-hidden="true"><svg aria-hidden="true" class="octicon octicon-link" height="16" ...

<h3><a id="1-introduction-deploying-meituans-agentic-open-source-moe-model" class="anchor" href="#1-introduction-deploying-meituans-agentic-open-source-moe-m...

<p>GPT-OSS, the first open-source model family from OpenAI's lab since GPT-2, demonstrates strong math, coding, and general capabilities even when compared w...

<p>We are excited to announce a major update for SGLang, focusing on deep performance optimizations and new features for the recently released openai/gpt-oss...

<p>Today, we are excited to introduce our latest flagship models <a href="https://huggingface.co/zai-org/GLM-4.5">GLM-4.5</a> and <a href="https://huggingfac...
<p>Speculative decoding is a powerful technique for accelerating Large Language Model (LLM) inference. In this blog post, we are excited to announce the open...

<h2><a id="1️⃣-introduction-deploying-the-most-advanced-open-source-moe-model" class="anchor" href="#1️⃣-introduction-deploying-the-most-advanced-open-source...

<h2><a id="tldr" class="anchor" href="#tldr" aria-hidden="true"><svg aria-hidden="true" class="octicon octicon-link" height="16" version="1.1" viewbox="0 0 1...

<p>The world of LLMs is evolving at a remarkable pace, with Visual Language Models (VLMs) at the forefront of this revolution. These models power application...

<p>The impressive performance of DeepSeek R1 marked a rise of giant Mixture of Experts (MoE) models in Large Language Models (LLM). However, its massive mode...

<h2><a id="vision-that-drives-slime" class="anchor" href="#vision-that-drives-slime" aria-hidden="true"><svg aria-hidden="true" class="octicon octicon-link" ...

<h2><a id="the-tale-of-two-teams-why-model-serving-is-broken" class="anchor" href="#the-tale-of-two-teams-why-model-serving-is-broken" aria-hidden="true"><sv...
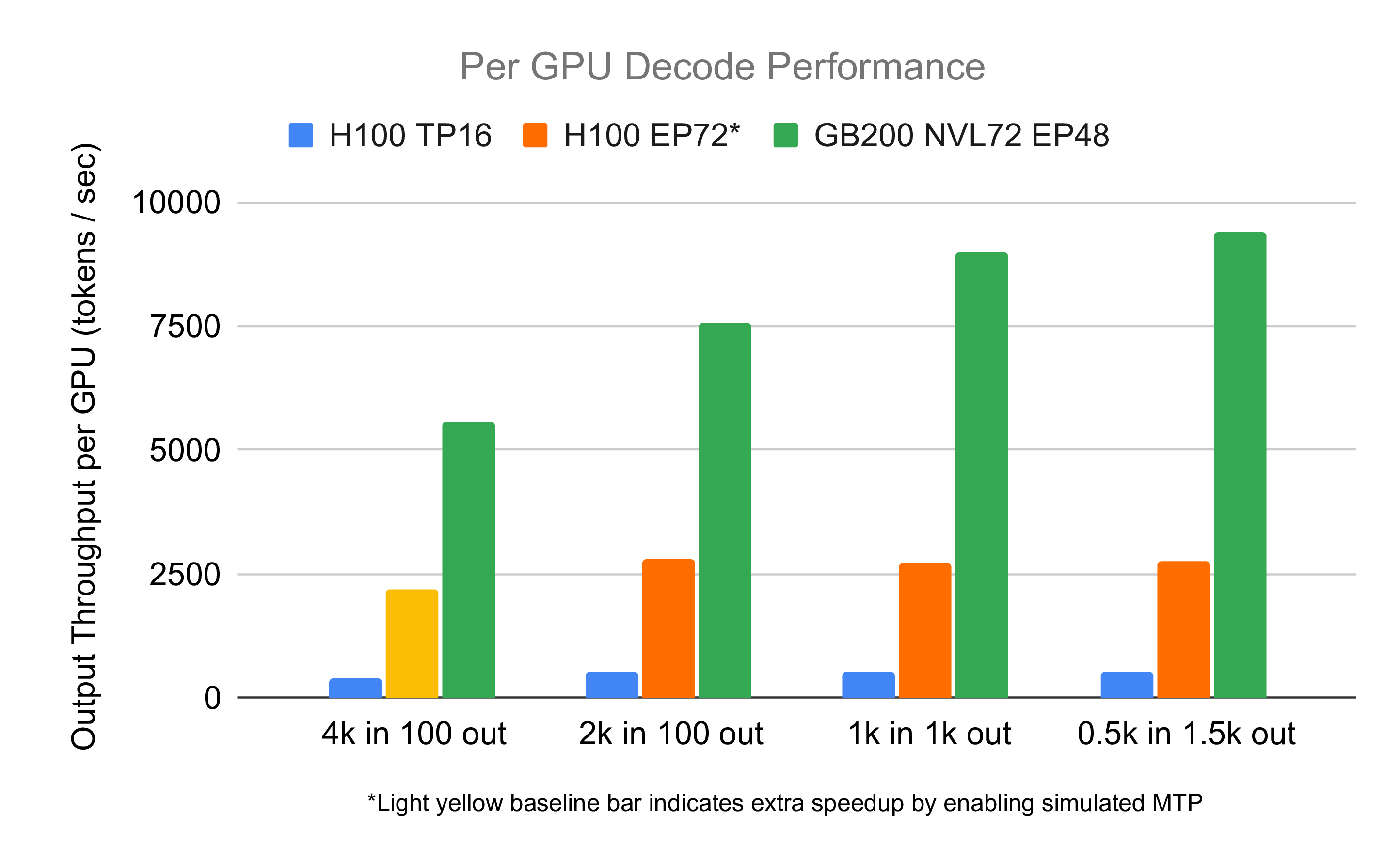
<p>The GB200 NVL72 is the world's most advanced hardware for AI training and inference. In this blog post, we're excited to share early results from running ...

<p>DeepSeek is a popular open-source large language model (LLM) praised for its strong performance. However, its large size and unique architecture, which us...