
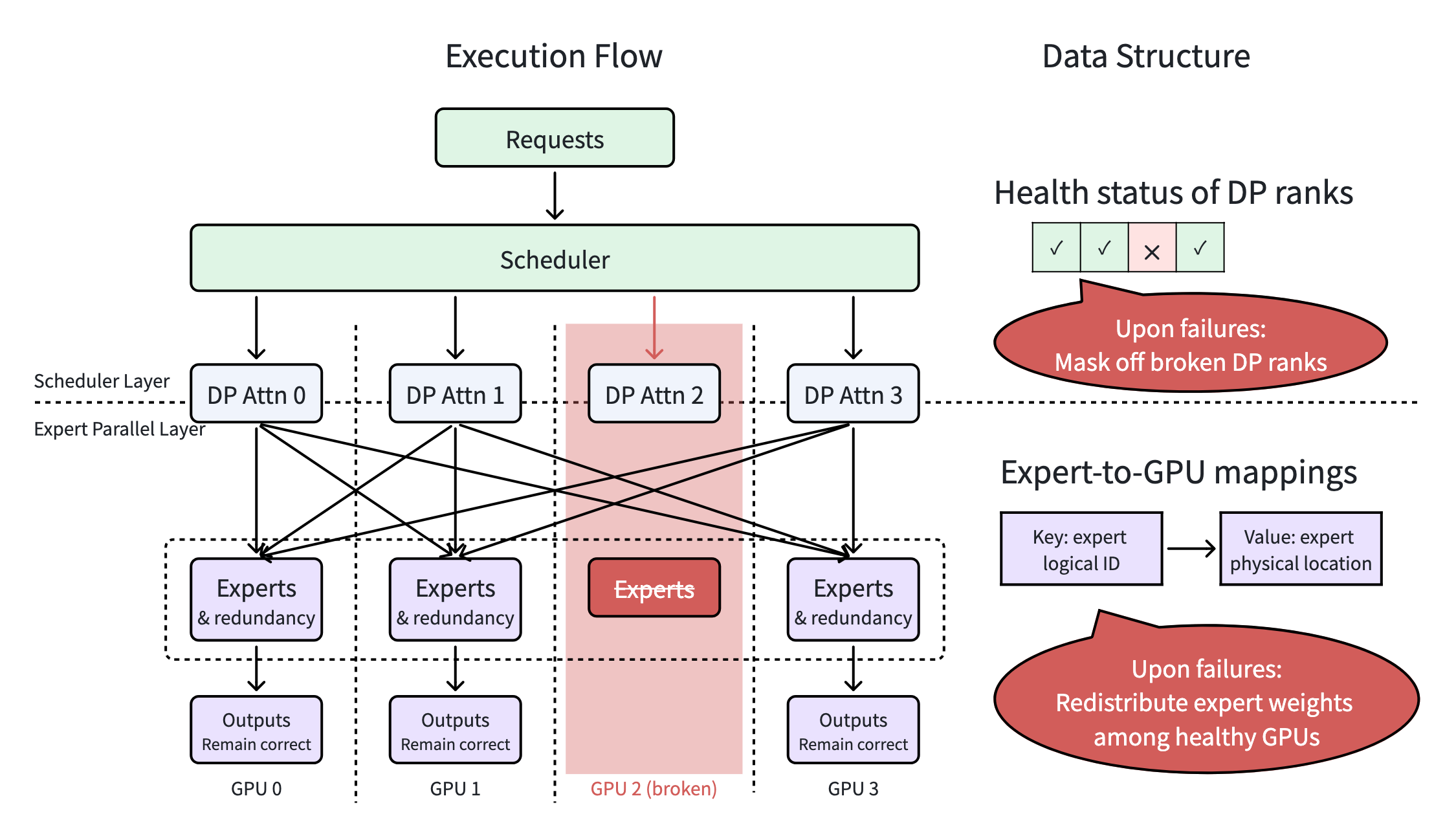
<h2><a id="1-the-problem-the-necessity-and-vulnerability-of-wide-ep" class="anchor" href="#1-the-problem-the-necessity-and-vulnerability-of-wide-ep" aria-hid...

<p>Reinforcement learning (RL) has rapidly become a core stage of modern foundation-model development. While large-scale pretraining remains essential, today...